Abstract Link to heading
I am a huge fan of Graph Neural Networks (GNNs), and I am (a bit less) a fan of Large Language Models (LLMs), however they are hard to ignore. Both have different strengths, while GNNs excel when it comes to problems that have an inherent structure, LLMs thrive in cases where we treat everything as a sequence of tokens (maybe Bytes in the future). A natural question arises, what if we can combine these two? It turns out yes, initially I encountered the Graph Neural Prompting paper during my T5 journey (still not finished, just making a couple of detours) which is a cool idea on how to merge knowledge graphs and T5. As it turns out there is already comprehensive research done on how to merge GNNs and LLMs in the following paper: A Survey of Graph Meets Large Language Model: Progress and Future Directions and its companion github repo: Awesome-LLMs-in-Graph-tasks and I decided to create this blog post to clarify how the merging of these two technologies is done.
Why to combine GNNs and LLMs (or LLMs and GNNs) Link to heading
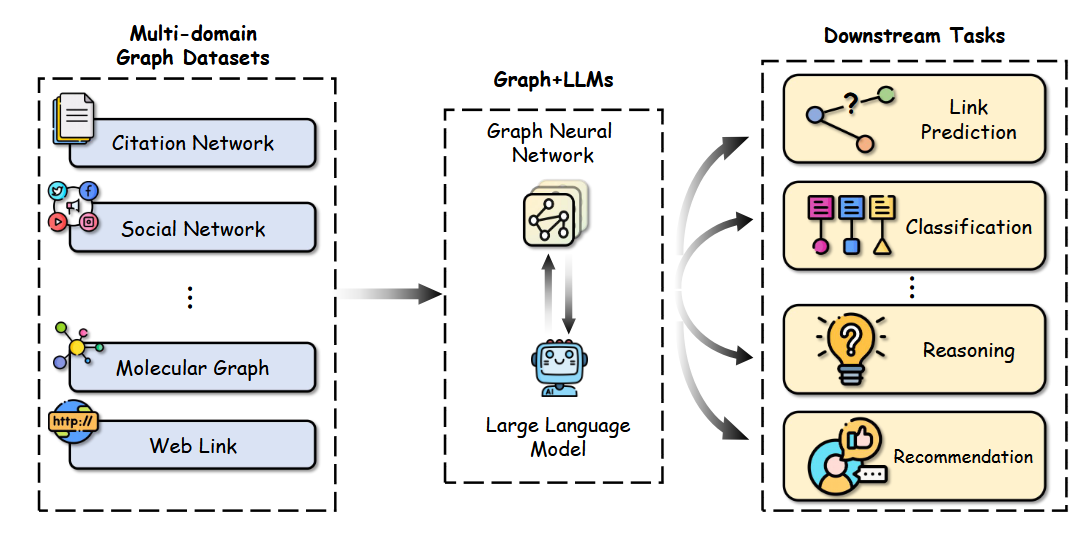
To answer this question we start by asking two additional ones:
- How can LLM help with a Graph problem?
- How can GNN help an LLM?
To answer those questions let us first analyze the pros/cons of both GNNs and LLMs. GNNs excel when it comes to capturing structural information, this can be the structure of a document, images on the side, text divided into different sections, or source code, which has an inherent graph/tree like structure (I already did write about GALa which merges GNN and LLM for Source code understanding and Generation), however they need a way to capture semantic information into their initial node embeddings. On the other hand, LLMs excel at capturing semantic information of text (or source code), however they fail (were not designed to is a better word) to capture complex hierarchical dependencies.
Just from the description above, we can clearly see a simple, but efficient solution where we use LLMs to generate the initial node embeddings for GNNs. Indeed this is powerful, and it is a widely used and somewhat proven approach. However it has a shortcoming, we only use the LLM to enhance the GNN, however with this we hardly use the LLM to its full potential.
GNNs and Pretraining Link to heading
With the rise of Pretrained Language Models (PLM) and their ease of adapting them to task specific problems (transfer learning) it is just natural that research tried to achieve something similar with GNNs, however this story is somewhat different and way more complicated to achieve. In GNNs we nearly always are interested in node embeddings, we start with some initial and after N rounds of training and given the actual graph structure and model layers we end up with some final embeddings. The final embeddings then can be used for node classification, where we put an additional model on top of the node embeddings, for link prediction, where we take a pair of nodes and their embeddings and use again an additional model to produce a binary variable if there is a link (if we would have different link types we can go with softmax (for mutually exclusive)). For Graph classification as whole the standard solution is to pool all the node embeddings to generate one graph embedding, the pooling can be taking an average over all embeddings, to more complicated hierarchical embeddings.
For pretraining GNNs there are two common approaches:
- Reconstruction, this is a classical approach where we have an encoder that embeds the graph into a latent representation, and a decoder that learns to reconstruct the original graph from the embedding, here are some examples:
- GraphMAE, which uses a Masked Graph Autoencoder
- S2GAE, again leverages a Graph Autoencoder but uses it to mask and reconstruct edges
- DUPLEX is an example for directed graphs, we learn a complex embedding, where the real part is used to encode the existence of an edge and the imaginary part the orientation of this edge
- Contrastive objective, this is very much the same as any contrastive learning objective, we try to create graph embeddings that for similar graphs are close, we can then later leverage the embeddings for downstream tasks
GNNs + LLMs = Better Together Link to heading
There are 3 main approaches to combine LLMs and GNNs (or GNNs with LLMs):
- LLM as an Enhancer
- LLM as a Predictor
- GNN-LLM Alignment
LLM as an Enhancer Link to heading
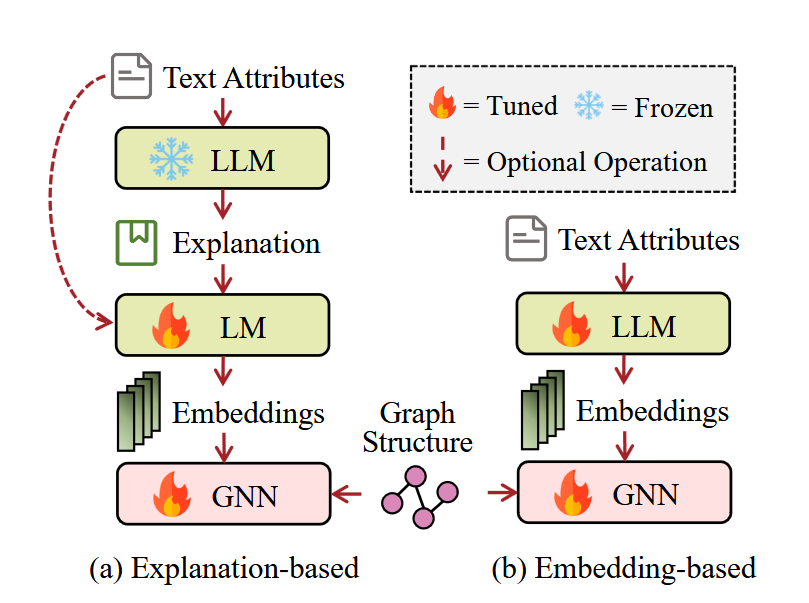 We already explored this approach a bit in the part where I talked about using LLMs generating the initial node embeddings, however there is more to it and we are going to explore it in more detail. In this setting we always work with Text Attributed Graphs (TAG), these are graphs that have text node features.
We already explored this approach a bit in the part where I talked about using LLMs generating the initial node embeddings, however there is more to it and we are going to explore it in more detail. In this setting we always work with Text Attributed Graphs (TAG), these are graphs that have text node features.
Embedding based enhancement Link to heading
Yes, you guessed right, we use an LLM to generate a node embedding! However there are some extra details we need to explore. First we may not want to embed the whole text, but we may decide to extract only relevant information, this approach is explored in depth in the G-PROMPT paper. Also we need to consider if we train the embedding model, this can be beneficial since it may learn to extract better features, on the other hand, it is way more resource hungry.
Explanation based enhancement Link to heading
Technically this also is an embedding based enhancement, but we do not embed the actual text itself but an explanation of the text that has been produced by a language model. Why would you do that? It is simple - we can use proprietary language models to generate the explanation. Is this actually a good approach? Well yes and no. Yes since the proprietary language models tend to be excellent and they may provide extra information, but no since it can balloon up the costs significantly, since most API based LLMs are expensive.
LLM as a Predictor Link to heading
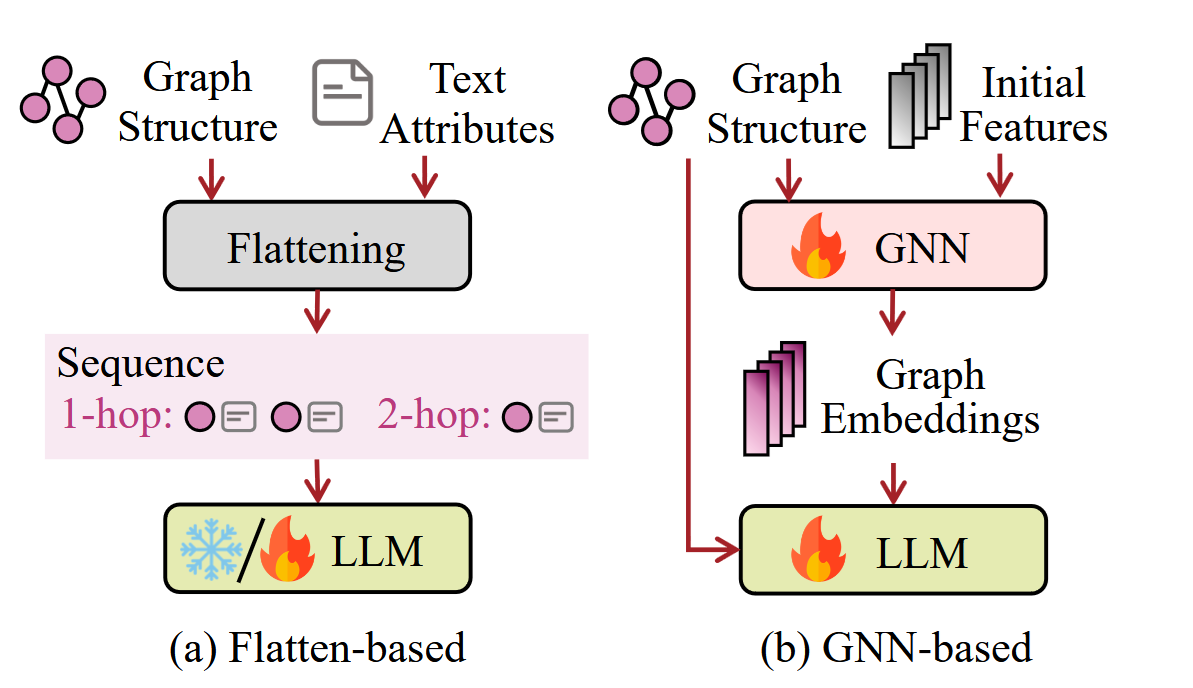
Here we want to use LLM to make predictions about graph related tasks. This is a very active area of research, and overall I believe it is one that makes most sense, especially the GNN-based predictions approach.
GNN-based Predictions Link to heading
Here we have a GNN model which produces node embeddings, we then take these node embeddings and embed them as tokens for an LLM. Before we go into examples let’s face the biggest problem of this approach: It can be used only with open weight models! Again a reason why I believe open source LLMs will dominate in the future, they are the most flexible and they can be used in scenarios that they weren’t originally designed for. As for the models here are some:
- GALLa, already mentioned somewhere above, it uses DUPLEX to generate node embeddings of a source code snippet, which are then passed to an LLM which can be then used to answer source code related questions, or even improve code translation (Python -> Java, Java -> Python) performance
- Graph Neural Prompting, again mentioned somewhere above
- Best of Both worlds, a rather recent paper, where the authors split a graph into subgraphs which are embedded, later they use an Attention-SSM hybrid to process this sequence
Flatten-based Predictions Link to heading
This is a somewhat less compelling alternative to GNN-based predictions, and the whole idea is to take a graph and represent it as, well text. So there is this Graph Markup language called Graph Modeling Language (GML), which we can directly use. A somewhat alternative approach is to use a model like GraphCodeBERT, which encodes graph structure as extra tokens with a specially designed attention mask.
Modeling graphs with GML has one upside, it can be used with any LLM also proprietary, however embedding large graphs will be a challenge, since it will require a lot of tokens, and still the relationships are human readable, but understanding complex hierarchies and structures will be challenging even for powerful LLMs.
Remark to special Attention Mask Link to heading
Since Coding LLMs have a special place in my heart, I ran across CodeSAM, where the authors build on top of the idea introduced in GraphCodeBERT, with minor modifications. They do not introduce special tokens encoding the Control Flow between variables, but they instead modify the attention mask. Actually they leverage two different attention masks, one that captures the AST and one for the CFD, and they alternate between these two across different layers. Very cool idea!
GNN-LLM Alignment Link to heading
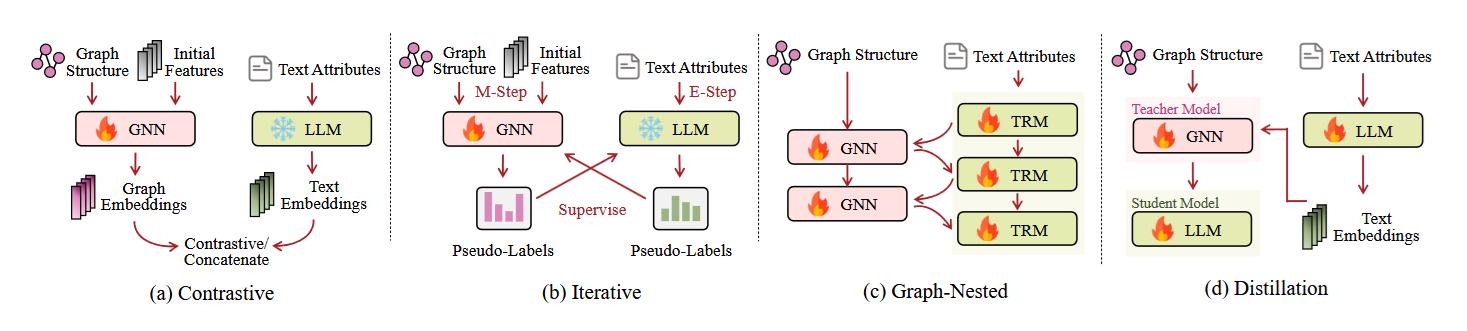
The high-level idea is to align (for example, minimize the distance between) the embeddings of both the GNN and the LLM. Why is this useful? Imagine you train an LLM and a GNN at the same time and align their hidden representations - the GNN will try to capture the hierarchical representation while the LLM focuses on the semantics. There will be some information sharing, where hierarchical information will bleed through into the LLM and some semantics will be captured by the GNN. In general, we have two main classes of alignment:
- Symmetric, where both LLM and GNN are equally important
- Asymmetric, where one modality plays support to the other
Symmetric Link to heading
Here we can split into two cases:
- Naive Concatenation, which is somewhat anticlimactic - we just train two separate models and concatenate their resulting modalities. With this late fusion, we have no information exchange between models prior to the concatenation.
- Contrastive objective, which is the canonical example of GNN-LLM alignment, where we pull the individual embeddings together in their latent representations. The canonical paper is ConGraT, in which the authors work with Text Attributed Graphs. They use contrastive pretraining to align the latent space of any GNN with any LLM (Encoder only or Decoder Only) and later use it for downstream tasks like node classification, link prediction, Community Detection and Language Modeling where they leverage only the aligned LLM.
Asymmetric Link to heading
We have 3 main cases:
- Graph Nested Transformers, where the canonical example is Graph-former. Here we embed a GNN into each transformer layer, where the role of the GNN is to further massage the output of the feed-forward networks.
- Graph Aware Distillation, which we can understand by looking at Grad. It consists of a GNN teacher model whose responsibility is to generate soft-labels for an LLM. We share parameters between the teacher GNN and the student LLM. Parameter sharing results in information bleeding between the GNN and LLM, forcing the LLM to pick up structural information and the GNN to better handle semantic information.
- Iterative Updates, demonstrated in THLM. Here we have a heterogeneous GNN that enhances an LLM, each pretrained using different strategies and producing labels for the other. After pretraining is done, we discard the GNN and finetune the LLM for graph-aware tasks, leveraging the information gained during joint pretraining. We can clearly see that the GNN plays a supporting role.
Final Remarks Link to heading
This just scratches the surface. If you are interested, I recommend visiting Awesome-LLMs-in-Graph-tasks on Github. An interesting new approach is combining GNNs with LLM Agents for planning: Can Graph Learning Improve Planning in LLM-based Agents?. Also follow Learning On Graph Conference - they do a great job informing the public about the latest research in the field of GNNs, and since Language Models cannot be ignored, there tends to be significant overlap.