Abstract Link to heading
State space models are really close to my heart, I even have a dedicated page about them. But when it comes to Language Models they lack some performance and that gave rise to SSM-Attention Hybrids. Until now it was conventional that in hybrid layers you sequentially combine Mamba(2) with Attention layers. Nvidia introduced Hymba - this paper changes the game by using Attention and Mamba2 in the same layer, each of them processing the same input tokens. The authors also give a human memory-like analogy why this approach is superior, which they also show in the benchmarks. And since Nvidia pushed this further they also introduced special Meta tokens, which alleviate Attention sink issues and its over-focus on BOS token and also setting up Mamba’s hidden state before it even starts processing the data.
Hymba Link to heading
There are 3 important aspects to Hymba:
- Mamba Attention Fusion
- Meta Tokens
- KV Cache Sharing
Here I ordered them by my subjective importance, let’s look at each of them in more detail:
Mamba Attention Fusion Link to heading
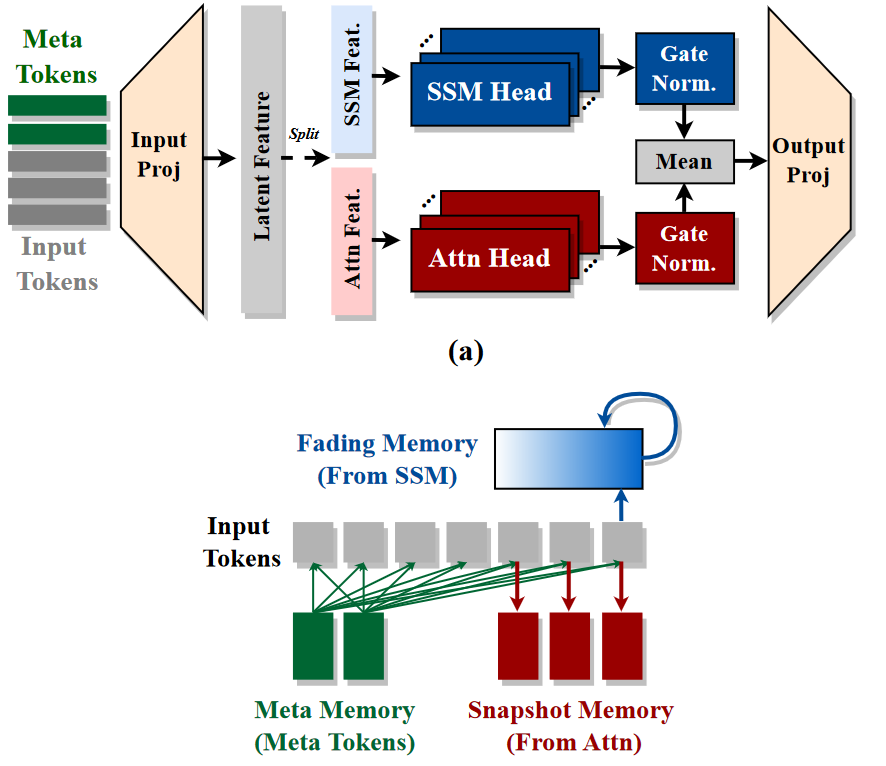
A normal SSM-Attention hybrid alternates between Attention and Mamba(2) between different layers, and in most cases we have multiple consecutive Mamba layers. The main reason for this is Mamba is more efficient and we just need only a couple of Attention layers to achieve (even overcome) the performance of a pure Attention model. Hymba does this differently, they use Attention and Mamba2 at the same time on the same layer. With this both process the same input tokens, here we can view this as running multi head attention, but some heads are not processed with self attention but with SSM.
What are the benefits?
- Attention and SSM are complementary, since Attention is stateless it provides a crystal clear recall however this stateless nature is inefficient since we need to cache previous tokens! Mamba2 has a global state, which serves as a compressed long term memory, however this memory fades with time and may forget details.
- Increased efficiency, previous research shown that replacing Attention with Mamba leads to increased throughput and reduced memory requirements. This is also true if we replace a couple of attention heads with Mamba, instead of whole layers, however fusion gives an additional benefit. We can replace full Attention with Sliding Window Attention (SWA). In SWA we constrain how far can attention look back, with this we risk that we may forget past information, but since we process the tokens with Mamba as well, we can leave the long range dependencies to it.
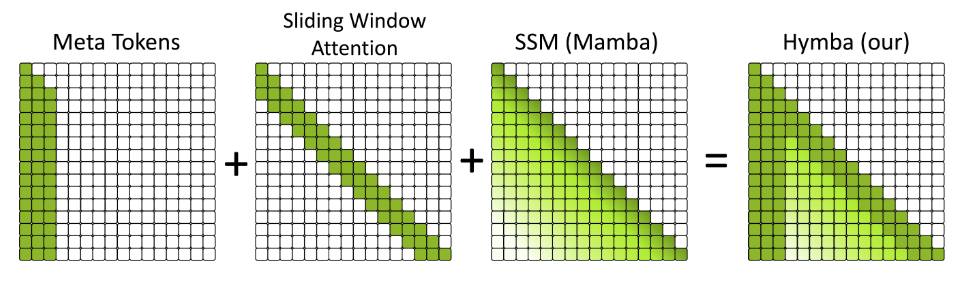
The picture above makes this even more clear, it includes Meta tokens and we cover them in a minute, but for now it is enough to say that they are always before: the prompt, or a sliding window if we process long sequences.
If we look at Mamba we can clearly see that the importance of prior tokens diminishes as we move farther in the sequence, SWA takes into account only the most recent tokens, if we combine these two we get an excellent short term recall and a fading long range memory. And since meta tokens are always present we cannot forget those!
Math Link to heading
I am kind of a math nerd, so I have to include some equations, let’s define the output of the fused layer:
$$Y = W_{\text{out}}(\beta_1 \text{norm}(M_{\text{att}}\tilde{X}) + \beta_2 \text{norm}(M_{\text{ssm}} \tilde{X})) $$
$\beta_1, \beta_2$ are learnable vectors that rescale each channel from the SSM and Attention output
$ \tilde{X} = [R, X] = [r_1, \cdots, r_{128}, x_1, x_2, \cdots, x_{n}] $, R are the Meta tokens, yep there is 128 of those!
$M_{\text{att}} = \text{softmax}(QK^T)V$
$M_{\text{ssm}} = G \odot \alpha(A,B,C,\Delta) W^{\text{SSM}} \tilde{X}$
$G$ is the output gate
$A,B,C,\Delta$ are the SSM parameters
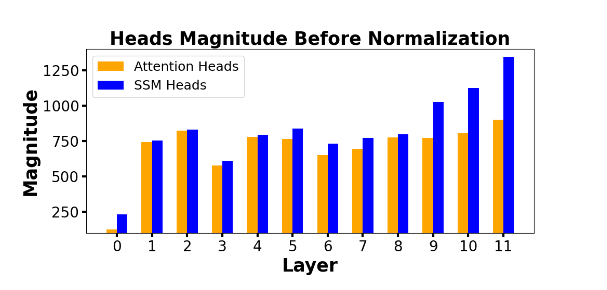
One thing that stands out is the extra normalization of the SSM and Attention output, this is needed because the output of Mamba tends to be larger than the output from Attention especially in later layers.
Fusion Strategy Link to heading
There is a tradeoff between how much Attention and Mamba to use, more Attention larger cache, slower to generate, with more Mamba we have a risk of not picking up the right information from a local context.
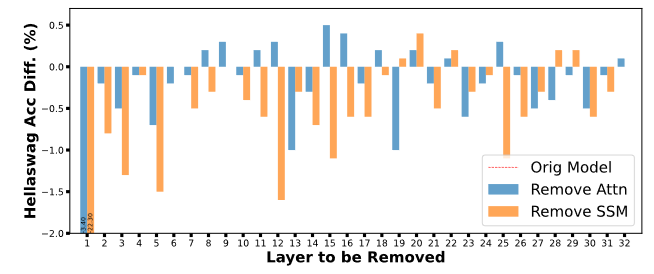
This graph above shows what is the penalty we pay (sometimes we gain) by using less Mamba (more Attention heads) or less Attention (more Mamba heads). Mamba is more important in the initial layers, these first layers are theorized to be more important for language modeling with later layers being more useful for the next token prediction task.
I mentioned before that we use SWA, however that is not strictly true we also have full attention, and that exactly in 3 places: First, Middle and Final layers.
Meta Tokens Link to heading
As mentioned above, meta tokens are fixed tokens that are always prepended to the prompt, and we can view them as the model’s general knowledge. Why is this useful? As before, meta tokens are processed simultaneously by Attention and Mamba. For Mamba, they are responsible for bootstrapping the initial hidden state, while for Attention, they help mitigate Attention Sinks. What is that? Well, attention tends to put too much weight on tokens that are not very important. Let’s look at an example:
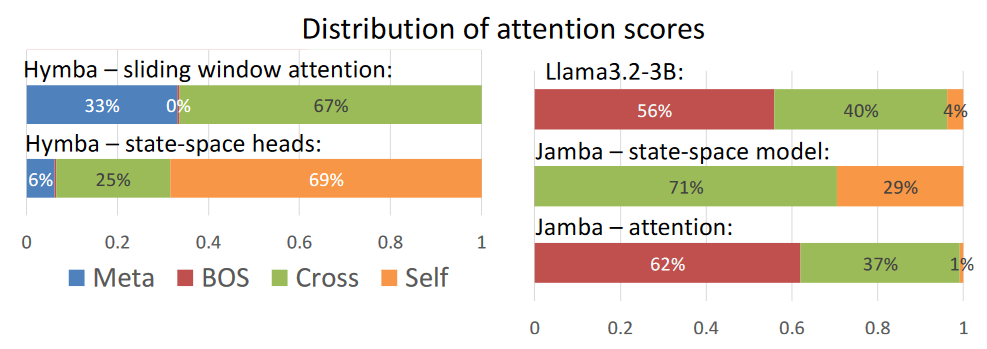
Let’s start with Llama3, where we can see that most of the attention weight is at the Beginning Of Sentence (BOS) token. Now this makes little sense, since semantically the first token in the prompt has nearly no value (maybe we should start all of our prompts with “Please”, or “My Life Depends on this”, etc). In Hymba, we can clearly see that we pay more attention to Cross tokens (below the main diagonal) and to Self tokens (hidden state) for Mamba2.
There is also a comparison to Jamba, which is a sequential SSM-Attention hybrid. We can clearly see that the Attention suffers from the same overfixation on BOS, which the Mamba layer tries to ease out by focusing on the rest, but at the price of not really modeling long range dependencies well!
Activations Link to heading
Let’s do a small breakdown of how the meta tokens are actually used:
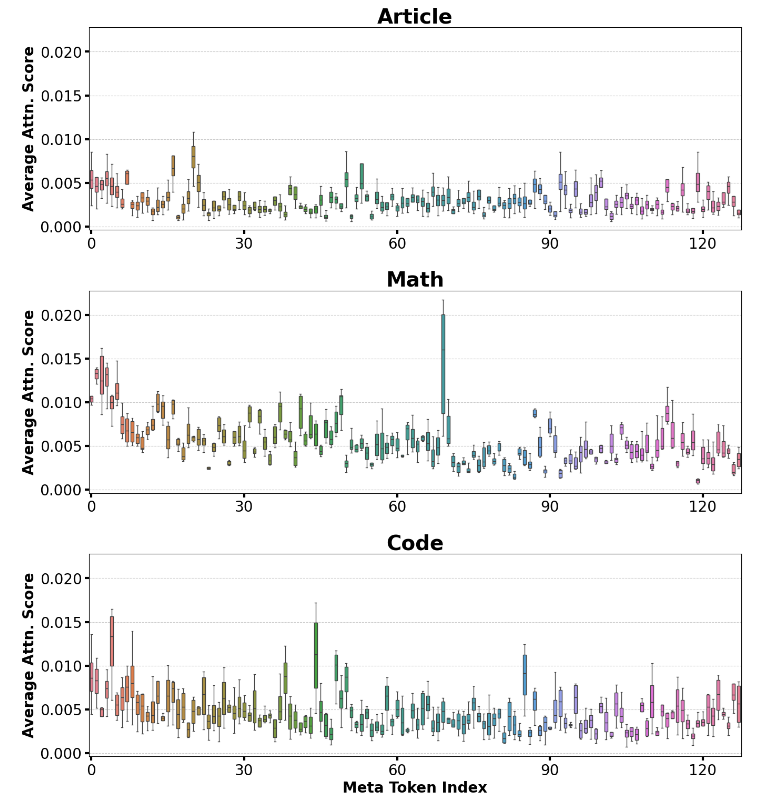
We can see the attention weight for different tasks, and there is a clear difference, indicating that different problems leverage different information stored in meta tokens.
Remark Link to heading
Here I see a clear research direction, where we can provide different meta tokens for different tasks, technically this is already being researched in Graph Neural Prompting where we prepend special tokens that are constructed from a knowledge graph and in GALLa which encodes a graph created from a programming language snippet as special tokens at the beginning of the prompt.
KV Cache Sharing Link to heading
This is the last part, and I guess the least groundbreaking. Long story short, we share the KV cache between two adjacent layers.
What is however more important, the overall performance gain from fusion, SWA and cache sharing means that the KV cache is nearly 20x smaller than in a pure Attention model and we also achieve nearly 3x higher throughput!
Model Link to heading
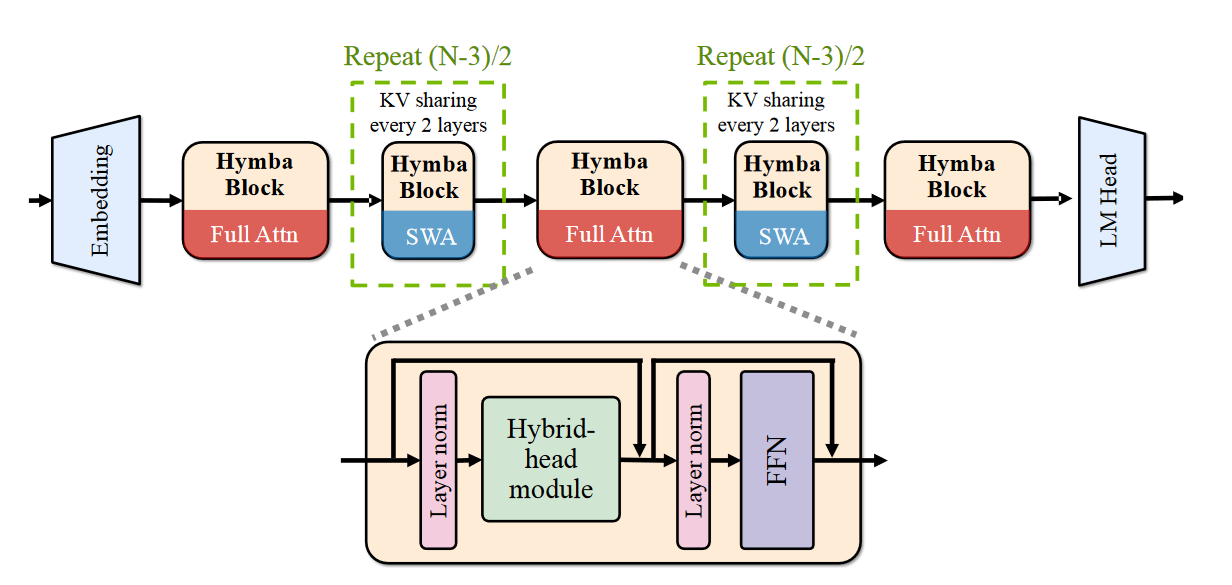
Here is the overall model:
Benchmarks Link to heading
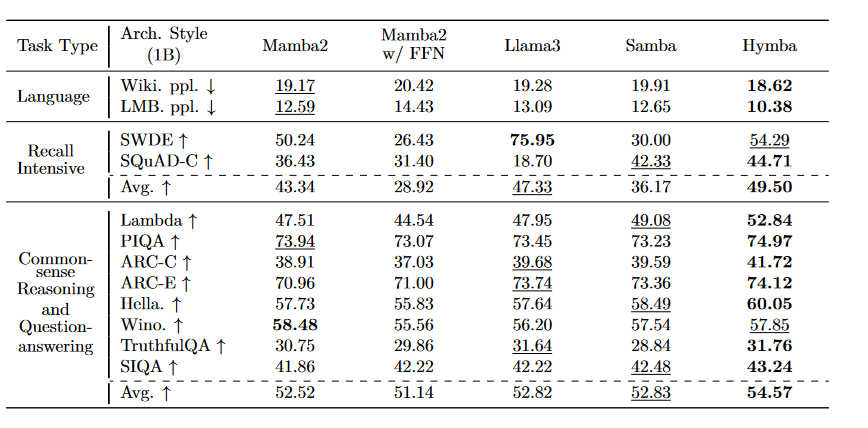
As for the performance benchmarks, we have a couple of them. First, to assess the real performance we pretrain multiple models on 100B tokens from SmolLM-Corpus
Needle in the Haystack Link to heading
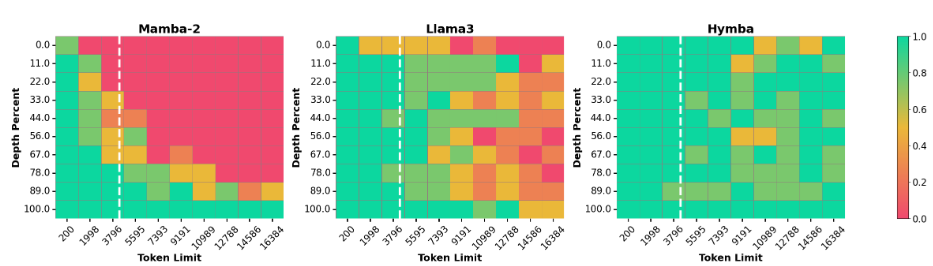
Performance on retrieving a specific value “needle” from the input “haystack”:
Instruction Tuning Link to heading
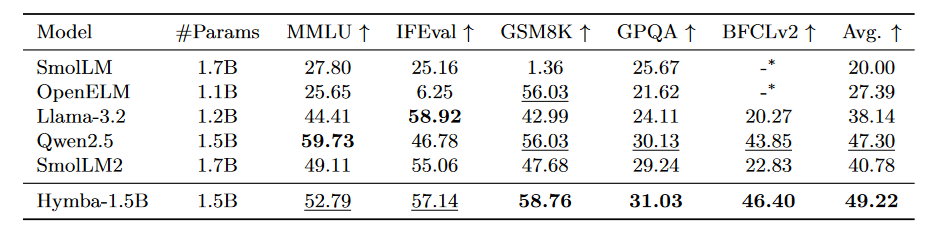
By taking it further and applying Directed Preference Optimization (DPO) we can compare its performance to current state of the art sub 2B language models, where Hymba is the clear winner.
Recap Link to heading
With fusing Mamba2 and Attention on the same layer we get a synergistic effect. Mamba is responsible for long range recall, and Attention serves as a short term memory with perfect recall. Since Attention is not responsible for modeling long range dependencies we use Sliding Window Attention, except in the first, middle and last layer. By incorporating meta tokens we avoid Attention sinks in our attention layers, and make focus on more actually important tokens, and we as well fortify the long range modeling behavior of Mamba. By introducing a shared KV cache between 2 adjacent SWA layers we achieve a 20x times reduced cache size and the overall throughput is 3x higher than a comparable vanilla Attention model.
Final impressions Link to heading
When I first found about this paper, I was super excited, and as I took the paper and dug into the details my excitement just kept growing.