Why does T5 need a longer context? Link to heading
In my previous post T5 the Old New Thing we already explored why T5 is awesome. But one downside is its limited context length of 512 tokens. However, it does have a limitation - its context length is restricted to 512 tokens. This can’t be directly compared to the context length of a decoder-only model, as T5 is an encoder-decoder model. This means that the encoder can process an input of up to 512 tokens, and the decoder can generate an output of up to 512 tokens, making the total context length 1024 tokens. In this article, we will discuss two extensions:
Both LongT5 and CoLT5 explore methods to extend the context length of the encoder part of T5. This implies that we are investigating ways to process longer input lengths, not necessarily to generate longer texts. This approach is particularly beneficial for tasks such as text summarization or document question answering.
LongT5 Link to heading
Originally published in 2022 and it uses a new pretraining strategy called Pegasus and explores using Local Attention and a unique TGlobal attention in the encoder.
Pegasus Link to heading
Pegasus is a pretraining strategy specifically tailored for abstract summarization. In this approach, we mask out key (principal) sentences from a document and teach the model to reproduce them as a single string, as if creating a summary.
Local Attention Link to heading
Local Attention is essentially a sliding window attention mechanism. This means that any given token can attend to a neighborhood of $l$ tokens.
TGlobal Link to heading
In TGlobal, we divide the input tokens into chunks of length $k$. For each chunk, we compute a global token by summing up the individual token embeddings. When performing attention, we take a Local Window $l$ and append all the global tokens to it.
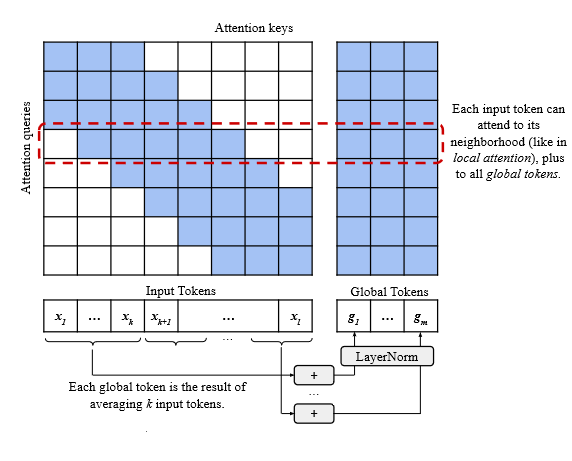
Cons Link to heading
As we do not perform full attention, we experience a slight performance degradation, and we require a few additional parameters. In terms of computation, we calculate the global tokens on the fly, but they can be computed just once per input tokens per layer and cached.
Pros Link to heading
We can process significantly larger input lengths.
Notes Link to heading
It’s worth mentioning that there is a variant of LongT5 that solely uses Local Attention, without Global Tokens. This variant can be scaled up to handle even longer sequences, but it also results in a more pronounced performance drop.
CoLT5 Link to heading
Paper from 2023, and it builds upon LongT5 by bring in ideas like Mixture of Experts and Multi Query Attention.
Conditional Computation Link to heading
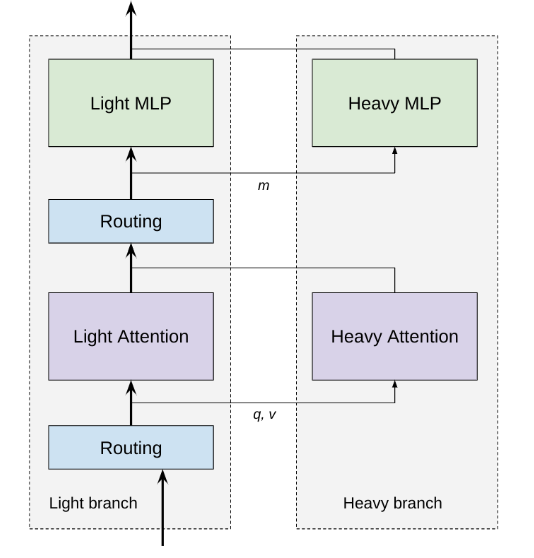
The the idea behind Conditional Computation is that not all tokens carry the same importance, and therefore, we don’t need to allocate the same computational resources to each of them. In the context of CoLT5, we have two branches: a light branch and a heavy branch. The light branch is applied to all tokens, while the heavy branch is only applied to important tokens. This branching occurs in two places: the attention layer and the feed-forward layer (Technically three places, since we route separately for queries and key-value pairs).
Attention Link to heading
The light attention branch has fewer heads than the heavy branch. Moreover, the light branch employs only local attention, while the heavy branch utilizes full attention.
Feed Forward Link to heading
In the feed-forward layer, the light branch has a lower hidden size compared to the heavy branch.
Routing Link to heading
The core of Conditional Computation lies in determining which tokens are important and which are not. To do this, we create a scoring function for each token. This function takes the value of the token $X_i$ and maps it to a d-dimensional embedding.
$$ s_i = X_i . u_d $$
- $s_i$ is the score for token $i$
- $u$ is the embedding function
Once we have the scores for all tokens, we need to select the top-k tokens. This isn’t straightforward since $s_i$ has a dimensionality of $d$, and we can’t simply pick the top-k values (we also need to normalize this score). The authors employ an iterative soft top-k algorithm from lei2023conditional and qian2022multivector. In short, this is an optimization problem where we solve the Dual Problem using Coordinate Descent.
Coordinate Descent Link to heading
Coordinate Descent is a gradient free optimization algorithm (Yes it does not use Gradient Descent), the intuition is that if we have an function $f(x_1, \cdots, x_n)$ we can transform this problem into a single variable optimization problem by fixing all other variables except one. Than we use a root finding algorithm like Brent Dekker (Thechinally this is a bracketing algorithm combined with secant method and quadratic interpolation) to find the optimal value for this variable. We repeat this process for all variables.
Coordinate Descent Link to heading
Coordinate Descent is a gradient-free optimization algorithm (yes, no Gradient Descent). The idea is that if we have a function $f(x_1, \cdots, x_n)$, we can transform this problem into a single-variable optimization problem by fixing all other variables except one. Then, we use a root-finding algorithm like Brent Dekker (technically, this is a bracketing algorithm combined with the secant method and quadratic interpolation) to find the optimal value for this variable. We repeat this process for all variables.
Least Absolute Shrinkage and Selection Operator (LASSO) Link to heading
Many of you have probably used this algorithm without even realizing it. If you’ve ever used LASSO regression (which is just linear regression with L1 regularization), the fastest way to solve this problem currently is using Coordinate Descent. Why is this the case? Well, firstly, the L1 norm is convex but not smooth, so we can’t use Gradient-Based Optimizations, but we can use Coordinate Descent. There are other ways to solve this problem, like using Proximal Descent or Subgradient Descent (yes, L1 is not differentiable at 0, but the subgradient is), but Coordinate Descent is simply faster.
Computation Link to heading
Since we have an optimization problem within our routing mechanism, we want this routing to be able to send signals. As a result, we want the routing scores to be part of the computation graph.
Feedforward Link to heading
$$X_i = X_i + FFd_{Light}(X_i) + \tilde{s_i} . FFd_{Heavy}(X_i)$$
- $X_i$ is the model state at token $i$
- $\tilde{s}_i$ is the normalized routing score (this is 0 for non-routed tokens)
Attention Link to heading
$$X_i = X_i = A_{Light}(X_i, X) + \tilde{s}^q_i . A_{Heavy}(X_i, \tilde{s}^{kv} . X)$$
- $X_i$ is the model state at token $i$
- $\tilde{s}^q_i$ are the normalized routing scores for the queries for token i set to 0 if not routed
- $\tilde{s}^{kv}$ are the normalized routing scores for the key-values for all tokens set to 0 if not routed
Performance Link to heading
Here we compare the performance between vanilla T5, LongT5 and CoLT5:
- T5 $12nd^2 + 2n^2d$
- LongT5 $12nd^2 + \frac{n^2}{8}d$
- ColT5 $7\frac{1}{4}nd^2 + \frac{n^2}{84}d$
Decoder Link to heading
During output generation, long input sentences can cause a memory bandwidth bottleneck. This can be mitigated by using Multi Query Attention (MQA) to expedite the decoding process. In MQA, all the query heads share the same key-value pair.
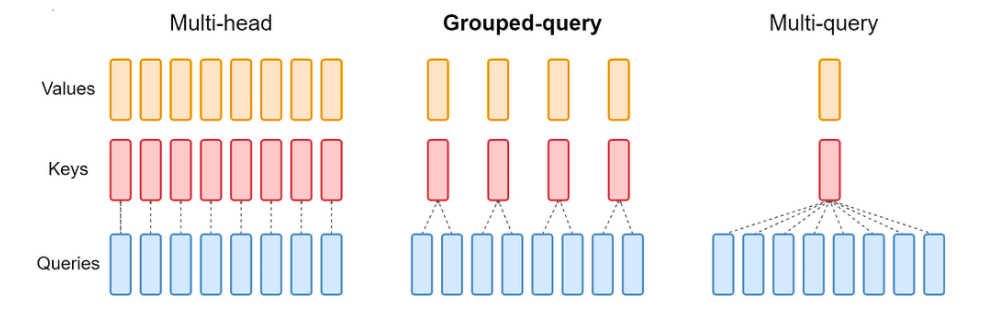
Performance Link to heading
Vanilla Multi Head Attention tends to have the highest accuracy but it requires the most memory and is the slowest to generate. By allowing query heads to share key-value pairs, we can reduce the memory requirements and improve token generation speed. However, this speedup comes at a cost, resulting in a loss of accuracy.
Cons Link to heading
With LongT5, we have open-source implementations from Hugging Face LongT5 and Google LongT5. Unfortunately, with CoLT5, things get tricky. I found the following repository ColT5, but the implementation is a best-effort reproduction (and an excellent one at that). However, as the author mentions, there are some open questions about the implementation.
Personal Thoughts Link to heading
CoLT5 is an excellent extension to vanilla T5 and shows a lot of promise. Its biggest downside is the lack of an official implementation and the absence of a pretrained model. LongT5, on the other hand, is a great extension to T5, but it starts to show its limits when we begin to scale up the input length to modern standards.
I would like to see a continuation of CoLT5 with exciting features such as Mixture of Experts and Sliding Window Multi Query Attention in the decoder part. With these, we would be able to efficiently process long input sequences and generate high-quality outputs efficiently.
Disclaimer Link to heading
Since I am not an english native speaker, I use ChatGPT to help me with the text (Formatting, Spelling, etc). However I did write every single word in this blog post, If you are interested you can check the the original text (and its history) here