Abstract Link to heading
We have already looked into Mamba and Mamba2. In terms of efficiency, with their linear complexity and the absence of Key-Value cache, they are a significant improvement over Attention-based models in terms of throughput and memory usage. However, not everything is perfect. Transformers have a certain advantage when it comes to in-context learning. In-context learning is the ability to adapt the model without retraining it. This is done by providing relevant (or not) context to the model in the form of a prompt.
In this post, we cover the following papers and blog posts:
- An Empirical Study of Mamba-based Language Models
- SAMBA Simple Hybrid State Space Models for Efficient Unlimited Context Language Modeling
- Jamba A Hybrid Transformer-Mamba Language Model
- Jamba 1.5 Hybrid Transformer-Mamba Models at Scale
- Zamba A Compact 7B SSM Hybrid Model
- Zamba2-small
- Zamba2-mini
An Empirical Study of Mamba-based Language Models Link to heading
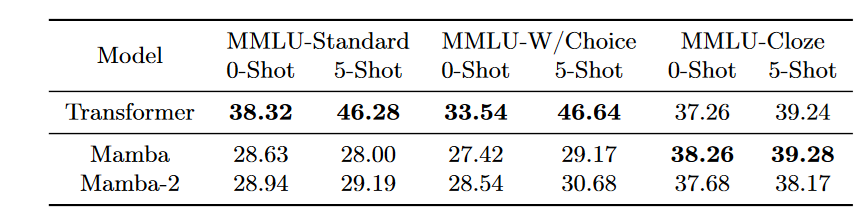
I have already mentioned that the biggest shortcoming of Mamba and Mamba2 is their lack of in-context learning capabilities. To showcase this, let’s look at the following table:

Overall, I am not a huge fan of this kind of academic benchmark. All 3 models have been pretrained on the same data of 1.1T tokens and have 8B parameters. If you look closely at the table, we can see in most cases the models perform similarly except for the MMLU benchmark.
The MMLU (Massive Multitask Language Understanding) benchmark aims to measure the general language understanding and reasoning capabilities of models by testing them on questions that require knowledge and reasoning across different fields (STEM, History, Literature, etc).
From the table, it is obvious that Mamba and Mamba2 perform more than 10 points below Transformers (Under transformers we can imagine a Llama-like model). But what is more interesting is the 5-Shot setting. In the 5-Shot setting, we provide the model with 5 examples of the same task and ask it to perform the same task on a new example. We can see that for Transformers there is a noticeable improvement, but for Mamba and Mamba2 the performance is almost the same.
MMLU in detail Link to heading
The accuracy of MMLU is calculated by prompting the model with a question that includes four answer choices A, B, C, D, and the model should choose one. In this case, what happens to Mamba(2) is that it gets confused and provides a wrong answer. If we look at a different formulation called “cloze”, where the model is asked to answer the question instead of choosing an answer, the performance of Mamba(2) drastically improves to the same level as Transformers.
Conclusion Link to heading
Since the performance of the cloze task variant is comparable for Transformer and Mamba(2) models, we can actually conclude that both Mamba(2) and Transformers contain the same knowledge and reasoning capabilities. The main difference is that Mamba is struggling with the precise in-context formulation of the MMLU task.
Why do Transformers perform so well? Transformers are stateless and they can easily copy the answer from the context. Whereas SSMs are stateful and they may struggle to determine what to keep and what to discard from their hidden state.
More Data Link to heading
There is an alternative approach to improve the performance of the Mamba-2 model, and that is to pretrain it on more data. The following table compares Mamba-2 (only 2 since it is more efficient to pretrain) with Transformers, both pretrained on 3.5T tokens and both having 8B parameters.

We can see that we came close in terms of 0-shot performance, but there is still a gap in the 5-shot performance. This just fortifies the point that SSMs are not as good as Transformers in in-context learning.
Hybrid Models Link to heading
Just from the numbers above we can see that a pure SSM model does perform really well, but it lacks the in-context learning capabilities of Transformers. A hybrid model would retain the best of both worlds. If we design a hybrid model we have a couple of options, each influencing the performance of the model:
- The ratio of SSM to Attention
- the more SSM layers we have, the faster the model will be and more memory efficient
- with more Attention layers, the memory will need a larger KV cache and there is the quadratic complexity of the Attention mechanism
- The type of Attention
- Full Attention is the most accurate; however, it has quadratic complexity
- Sliding Window Attention gives us linear complexity but for long context it is less accurate than Full Attention
- Choice between Grouped Query/Multi Head Attention etc
- The type of SSM
- we can choose between Mamba and Mamba2
- Mamba2 is way more compute efficient and more expressive given its larger hidden state; however, we may not need the extra expressiveness
- Positional Encoding
- SSMs do not use positional encoding since they do not need it
- Transformers need positional encoding since Attention is permutation invariant
- The number of MLP layers
- Transformers use MLPs for mixing information across channels, SSMs do not need this since both sequence and channel mixing is done by the SSM
- MLPs are super efficient to compute
Sample 8B Mamba2-Attention Hybrid Model Link to heading

This is a sample architecture where:
- we have 24 (Mamba2 + Attention) layers with 4 Layers of Attention and 20 Layers of Mamba2
- we have 28 MLP layers
- we use Grouped Query Attention with 8 groups on 32 heads
- Mamba2 has State Dimension of 128
- we use no positional encoding
- GeLU activations
- Skip connections and RMSNorm before Mamba2 and Attention layers
Pretraining Link to heading
Long story short, the pretraining speed (FLOP utilization) is equal to the pretraining speed of an 8B pure Transformer model.
Efficiency Link to heading
The hybrid can generate tokens 8x faster compared to a pure Transformer model. Since we use only 4 Attention layers, the KV cache should be significantly smaller than in a pure Transformer model. Unfortunately, there are no concrete numbers; however, we are going to see for later models that there tends to be a 10x reduction in the size of KV cache.
Context Extension Link to heading
In general, the accuracy for pure Transformer models tends to drop as we approach the edge of the context window. With the hybrid model, we can go slightly beyond the context window (for a 4k context window we can go up to 5.5K tokens) and still retain near perfect accuracy. And since we do not use any positional encoding, we do not have to worry about theta scaling, NTK scaling, LongRoPE or any other positional encoding tricks.
Benchmarks Link to heading
One of the main reasons for hybrid models is to improve the in-context capabilities of SSMs. Let’s look at some benchmarks:

Long story short, the hybrid model performs better than the pure Transformer model across all benchmarks. We can already see that by just adding 4 Attention layers we gave the model in-context learning capabilities.
Long Context Link to heading
One of the main selling points of SSMs is their efficiency, which is especially important for long sequences.
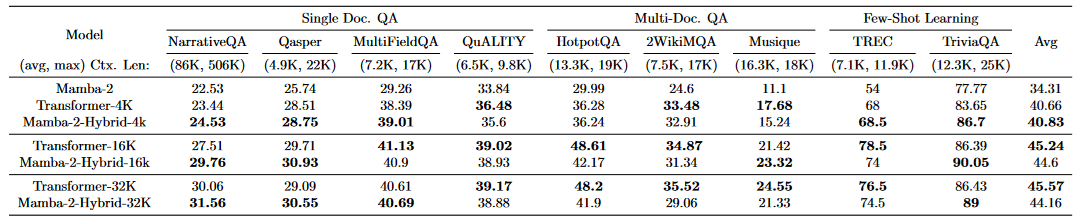
Here we see that hybrid models lag behind pure SSM models. One reason for this is the actual formulation of the long context problem, which is done by concatenating random sentences. This approach may confuse the hybrid model, since it sees random sentences and it may struggle to determine what to keep and what to discard from its hidden state. A simple reformulation of the problem, where we first ask a question and then provide the context, could help to address this issue, but the approach above is standard for transformer models.
Conclusion Link to heading
We have showcased the shortcomings of pure SSM models and explored the benefits of hybrid models. The general consensus is that hybrid models offer a nice uplift in performance compared to pure SSM or pure Transformer models. Especially in the in-context learning capabilities, where pure SSMs struggle with the precise formulation of the task. However, the hybrid models are far from perfect and they struggle with long context problems, where there is a lot of random information that the model has to process.
Samba Link to heading
Samba is an interesting approach to hybrid models, especially because it uses the same 3.5T pretraining data as Phi3. In hindsight, if we compare Samba to other hybrids, it uses far more Attention layers than the remaining models.
Model Link to heading
The core of the model is a Samba block. This is made of 4 parts:
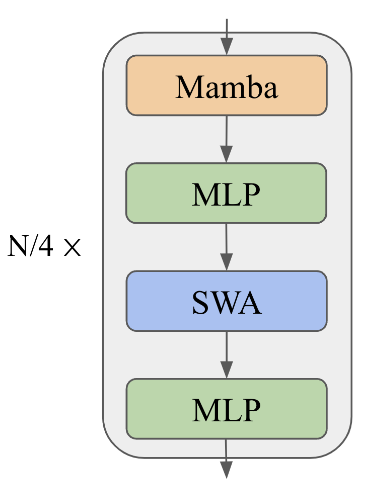
- Mamba
- MLP
- Sliding Window Attention (2048 window size)
- MLP
From this, we already see that we have the same number of Mamba layers as Attention layers. In total, we have 12 blocks as above and 48 layers in total. There is a Residual connection between blocks, and a Pre-Norm layer before each block. The MLP blocks utilize SwiGLU activations, and we have RoPE positional encoding at the beginning of the model.
Attention Link to heading
Using Sliding Window Attention (SWA) instead of full attention is rather unique for a hybrid model. The main argument for SWA is its stable perplexity during context extension, whereas with Full Attention, the perplexity kept increasing. In my opinion, the main culprit here is the RoPE positional encoding, which requires tricks for context extension.
It is worth mentioning that when compared to pure Attention models, we can have SWA with 2x fewer query heads and still have the same performance.
Remarks Link to heading
SWA is a great approach to reduce the quadratic complexity of the Attention mechanism to linear complexity. However, since the model cannot look beyond the window size, it may struggle especially with long context problems. On the other hand, the Mamba layers are stateful, and their dynamics are determined by their hidden state and the current token. By mixing Mamba with SWA, the Mamba layer now has access to more concrete information about the previously seen tokens.
Performance Link to heading
It is on par with Phi3 or better on all benchmarks.

However, it has greater throughput, which is most noticeable at context beyond 8K, and by having half as many attention layers, with fewer query heads than Phi3, the size of KV cache should be smaller.
Long Context Link to heading
The last two benchmarks in the table above relate to Long Context understanding, in both we are on par with Phi3. On the synthetic PassKey retrieval benchmark, Samba achieves near perfect accuracy up to a context length of 256K tokens.
Final Thoughts Link to heading
The model by itself looks fine; just getting a model comparable to Phi3 is a great achievement. However, the downside is that the model is not publicly available.
Jamba and Jamba 1.5 Link to heading
Both Jamba and Jamba 1.5 bring Mixture of Experts (MoE) into the mix. What is MoE? The basic idea is that we trade extra memory for faster token generation without losing quality. This is done by introducing extra parameters (experts) in the MLP layers. Each time we perform channel mixing with these MLP layers, we choose a subset (top-k experts) of these parameters to generate the next token. Mixture of Experts was popularized with LLMs with Mixtral (2023); however, their roots with Transformers started (at least to my knowledge) with Switch Transformers (2021), and the concept dates back to Adaptive Mixture of Experts (1991).
Model Link to heading
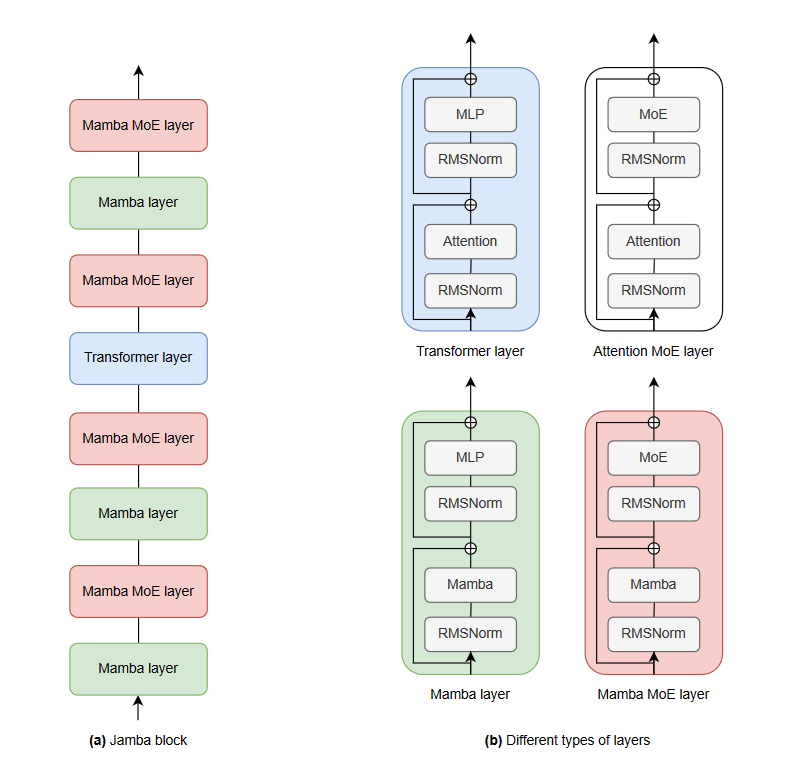
The model is centered around a Jamba block. That is a block of 8 layers, of which 7 are Mamba layers and 1 is a Full Attention (Grouped Query Attention) layer. Each Mamba and Attention Layer starts with an RMSNorm followed by Mamba or Attention, with an RMSNorm again and lastly an MLP (SwiGLU activation), with Residual connections in the mix. In a Jamba block, we replace the MLP with MoE (top 2 from 16 experts) every two layers.
Positional Encoding Link to heading
Since the model starts with a Mamba layer, we do not use explicit positional encoding. It is implicitly done by the first Mamba layer.
Context Length Link to heading
The officially released model supports context length up to 256K tokens; however, the paper showed that the model can be scaled up to 1M tokens. What is more important is that Jamba, which has 52B parameters of which 12B are active, can be used on a single 80GB GPU with context length up to 128K tokens.
Efficiency Link to heading
KV Cache Link to heading
Since the whole model contains just a few Attention blocks, the KV cache for 256K context length with 16-bit precision is just 4GB, whereas Mistral or Mixtral requires 32GB and Llama2 7B requires 128GB.
Throughput Link to heading
The throughput is comparable to Llama2 or Mixtral for a short context, but it gets much higher after we pass the 32K context length threshold.
Benchmarks Link to heading

In most cases, it is on par with other Open Source Models. However, it lags behind in GSM8K (Math). For the synthetic Needle-in-a-haystack, we have nearly perfect accuracy up to 256K tokens.
Stability Link to heading
The authors report that when scaling Mamba-based models above 1.3B parameters, they experienced Loss Spikes.
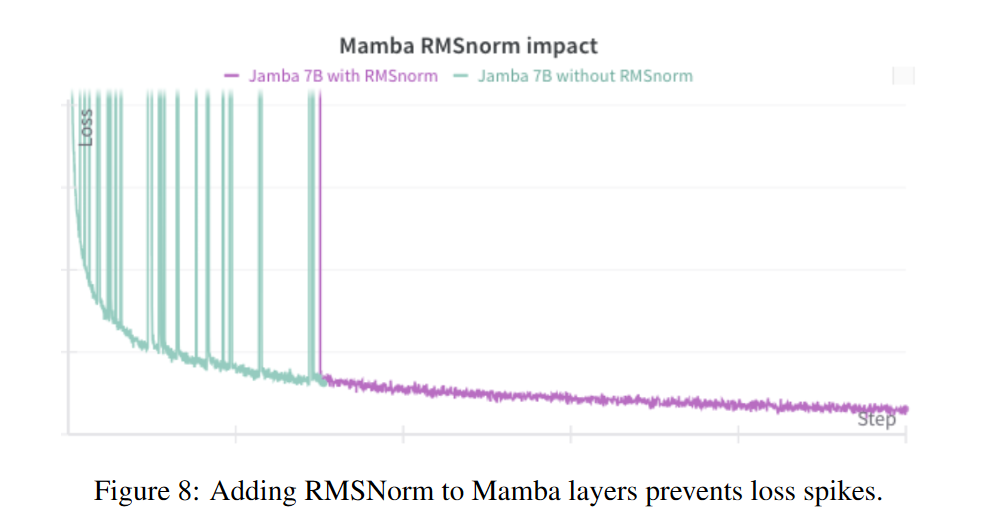
To stabilize the training, they introduced RMSNorms inside the Mamba layer.
Jamba 1.5 Link to heading
Jamba 1.5 comes in two parts. The first is the original Jamba but with additional instruction fine-tuning, pushing its benchmark results higher. And Jamba 1.5 Large is just Jamba scaled up to 398B parameters, of which 52B are active at a time, with a larger hidden state of 8192 and 64 Query Heads for 8 Key-Value heads.
Mamba2 Link to heading
Jamba 1.5 was released after the release of Mamba2, and overall Mamba2 is more powerful than Mamba, so we would expect them to use it. However, the authors claim that while Mamba2 is more expressive due to its larger hidden state, this extra expressivity is less important when we have Full Attention in the system. Personally, I look forward to future research from different AI labs to confirm this viewpoint.
Quantization Link to heading
Having a 398B model is not cheap to run; because of this, Jamba 1.5 Large comes with a custom Quantization Technique that stores the MoE weights in Int8. These weights are just-in-time dequantized to BF16 during inference, which happens in a fused kernel with minimal overhead.
Training Link to heading
Here we have multiple training stages, each stage trying to teach the model some different behavior.
Stage 1 Link to heading
The first stage uses publicly available data with a cutoff of March 2024, and it contains multiple languages. The goal is to teach the model general knowledge.
Stage 2 Link to heading
In this stage, we pretrain on long documents, giving the model long-range capabilities.
Stage 3 Link to heading
They heavily lean into synthetic data, with the assumption that it is high quality, and the idea is to teach the model specific skills like TableQA, DocumentQA, Tool Use, and Steerability (model should be helpful to draft documents).
Remarks Link to heading
During training, they do not use Reinforcement Learning (Proximal Policy Optimization) nor Direct Preference Optimization, just supervised fine-tuning. Also, the model shows remarkable multilingual capabilities even though only the first stage contained data in languages other than English.
Stability Link to heading
The model was trained in BF16, for which the maximum value is 64K. However, the authors experienced explosion of some activation losses which were way beyond the maximum value. Because of this, they introduced an Activation Loss Penalty (L2 norm) to keep the activations reasonably small.
Performance Link to heading
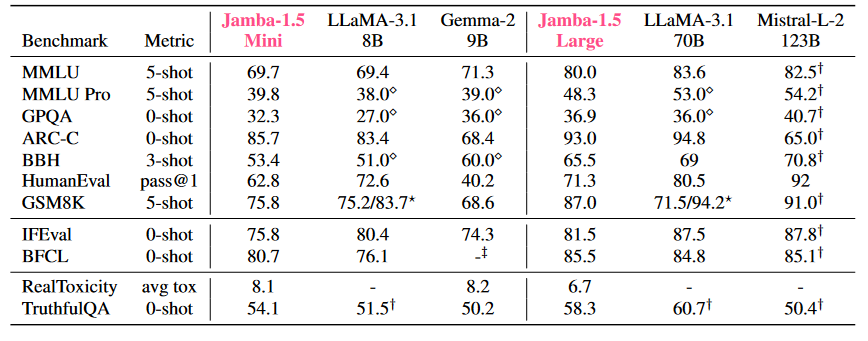
Again, as with Jamba, we see strong performance comparable with leading open-source models but with a significantly smaller memory footprint and higher throughput, especially at large context lengths.
Final Thoughts Link to heading
Jamba 1.5 mini is a great example of a Small Language Model (SLM) that is small enough to run on a Single GPU with 128K context. This is especially suited to extract information (structured generation) from large documents.
I just wish there would be a Nano version that could be run on consumer-grade hardware as well.
Zamba and Zamba2 Link to heading
Zamba is somewhat similar to Samba, but with the distinction that it tries to use Attention as little as possible. Also, Zamba(1) was pretrained on a budget of roughly 200K, which is compared to models like LLama, Mistral or Phi is extremely cheap. Currently, there are 3 versions: the original Zamba, which is a 7B billion model leveraging Mamba1; and Zamba2, which leverages Mamba2 and comes in two sizes, a 2.7B and a 1.2B mini version. There are some distinctions between the models; they have a unique feature, sharing of attention layers.
Model Link to heading
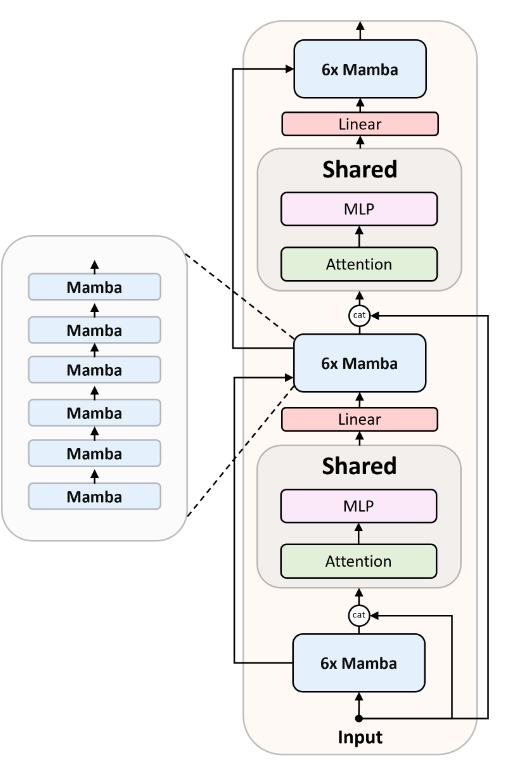
This model is quite different from what we have seen before. A Zamba block contains two parts:
- Part 1: We start with a Mamba Block that is made of 6 consecutive Mamba layers. After the Mamba block, we have a residual connection where we concatenate the output of the block with the original input, which is fed into the shared Full attention layer followed by an MLP.
- Part 2: Here we take the output from the previous part, and we elementwise combine it with the output from the previous Mamba block and feed it into a new Mamba block. The output of the Mamba block is concatenated with the original input and fed into the same shared attention layer as in part 1 followed by an MLP. And I forgot that there is a Linear Layer after each Attention layer.
Overall, we have 7B parameters, with 13 Attention blocks, each of them having separate KV caches, and with RMSNorm layers (The paper does not state it but I would expect them to be after the Attention and MLP layer).
Training Link to heading
Before we go into detail, I would like to praise the research team; they gave away a lot of details on the actual pretraining, especially the details on the annealing phase of the training.
Dataset Link to heading
Nothing groundbreaking, a mix of heavily deduplicated and synthetic data.
Phase 1 Link to heading
Here they use 950B of publicly available data (C4, Pile, Arxiv and PeS2o). We use Cosine learning rate decay; however, the learning rate decays significantly faster than pure Transformer models. Pretraining is done on 128 H100 GPUs for 30 days (this roughly costs 200K USD, which is extremely cheap compared to other models), using ZeRO-1 optimizer. ZeRO-1 partitions the optimizer states across multiple GPUs, and updates only a subset of these states, while keeping a full copy of the model on each GPU.
Phase 2 Link to heading
This phase uses high-quality Curriculum data, consisting of instruction and synthetic data, in total 50B tokens. What is worth mentioning is that the authors restarted the learning rate decay, with exponential decay, which is way faster than in Phase 1. The argument for using fast decay is that we have high-quality data, so we force the model to pay more attention to it. (This seems like a common approach with continuous pretraining, where we repeat the pretraining on new data)
Performance Link to heading
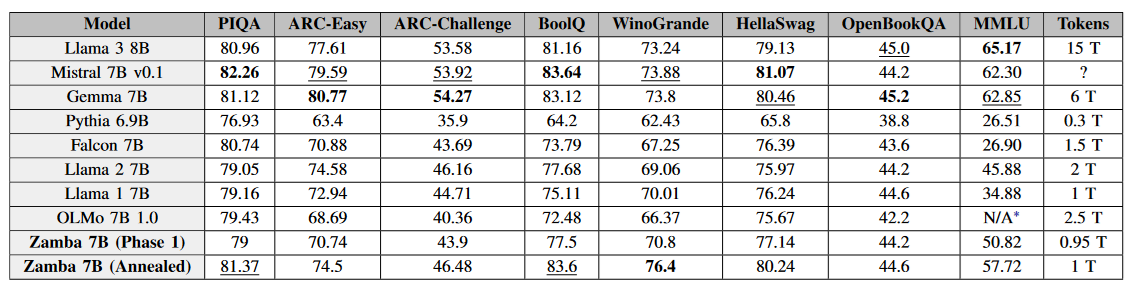
The model lags behind the current state-of-the-art models (Mistral and Llama3) but is on par with Llama2. The main argument is that the new models have been pretrained on vastly more data (Llama3 on 15T tokens), potentially of higher quality. This seems a common theme among new models from smaller AI labs that just do not have access to the high-quality data of the big and established labs.
Zamba2 Link to heading
Zamba2 is an extension of Zamba which leverages Mamba2 instead of Mamba. There are also additional changes, depending on the size of the model.
Zamba2-Small (2.7B) Link to heading
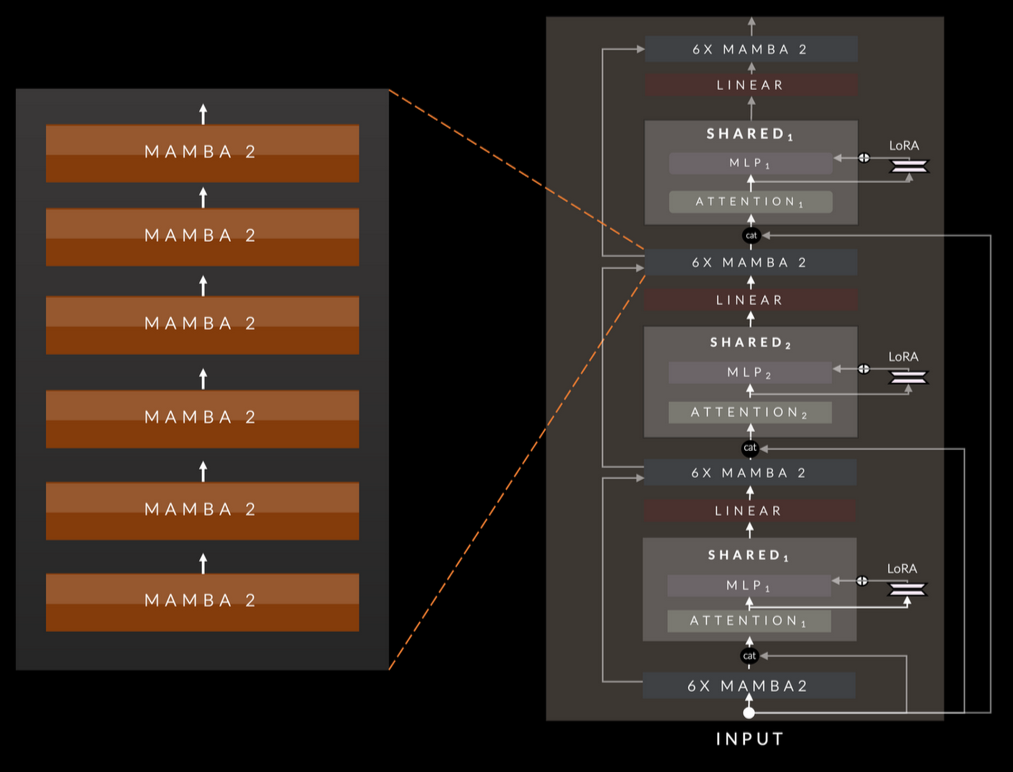
The main differences besides Mamba2 and the model size are the following:
- We have two shared attention layers
- The MLP blocks also include LoRA projection specialization layers. LoRA is an efficient way of fine-tuning models on a budget. The idea here is somewhat similar; by including projection layers, we can specialize the MLP layers (remember they are shared) at the cost of only a few extra parameters per layer.
Zamba2-Mini (1.2B) Link to heading
This is really a small model, especially suited for edge computing. Compared to Zamba2 Small, there are a couple of differences:
- Trained on vastly more tokens (3T + 100B for annealing)
- It has only 1 shared attention block but still keeps the LoRA projections
- Uses RoPE positional encoding before the Attention Blocks. This is particularly interesting since Mamba should be enough to handle the positional encoding, and it is not applied at the beginning of the model, but before the attention blocks.
Remarks on Small and Mini Link to heading
These two models have huge potential since they can run on consumer-grade hardware and on edge with unparalleled price-performance ratio. They are publicly available, and I can’t wait to take them for a spin.
Final Thoughts Link to heading
The idea behind the Zamba family can be summarized as: “One Attention layer is all you need”. The model is a great example of pushing Mamba(2) to its limits and unique application of LoRA and shared attention to keep the extra requirements on top of SSMs at bay.
Conclusion Link to heading
Hybridizing Mamba(2) with Attention is a great approach to make the model more efficient while retaining the same accuracy. However, there is no free lunch, and it may require rethinking the prompting strategies a bit, formulating the goal at the beginning of the prompt (maybe even mentioning it multiple times). The obvious improvements are gained by running hybrid models in settings where we need to process a large context but have constrained resources.
Mamba is a State Space model, however this state is “fake”, to find out more:
http://localhost:1313/posts/ssm-the-illusion/