Why T5 Link to heading
A couple of weeks ago I run into the following paper Tiny Titans. It compares multiple smallish (up to 1B parameters) open source LLMs with bigger proprietary ones on meeting summarization. TLDR; the small models tend to perform worse in zero-shot setting as well after fine-tunnig than big ones. Except for FLAN-T5-Large which after finetuning performs way beyond its league, beating even the biggest proprietary models (GPT-3.5).
This is not the first time I read an research paper that used T5 or build upon it. Some examples are:
All this research tickled my curiosity and I decided to learn more about T5 and its applications. In this blog post I will cover (to some extent) the following papers:
I will also mention other papers that are related to T5, but I will not go into details about them.
Introducing T5 Link to heading
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer is a paper introduced by Google in October 2019. The paper introduces a new approach to transfer learning in NLP called “text-to-text” transfer learning.
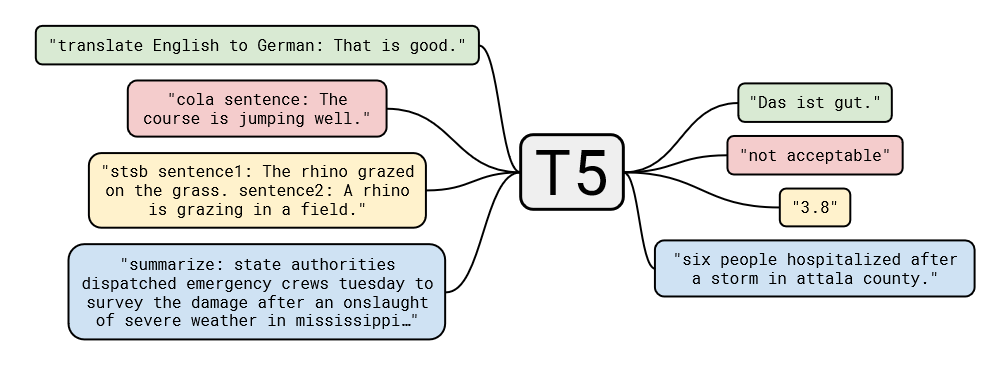
The core idea of T5 is to pretrain a model on a large corpus of text, and then fine-tune the model on a wide range of NLP tasks by converting the task into a text-to-text problem. This novel approach achieves state-of-the-art results on a wide range of NLP tasks.
In comparison the previous state of the art in NLP was dominated by models that are trained on a single task and then fine-tuned on the target task. This approach has several drawbacks, such as the need to collect and label a large dataset for each task, and the need to fine-tune the model for each task.
Lets given an example, and take a look an hypothetical text classification task. In the traditional approach, we would take an model like BERT, pretrain it on a large corpus of text, and then introduce an classification head on top of the model. In the text-to-text approach, we pretrain the model on a large corpus of text, and then fine-tune the model on the text classification task by converting the task into a text-to-text problem. For example, we could convert the text classification task into a text generation task by adding a prefix to the input text that specifies the task, and then training the model to generate the label. The downside of the later is that the label may be made up by the model (Halucinations where a thing 5 years ago as well).
There is an obvious benefit to the text-to-text approach as it does not require introducing a new architecture (or additional layers) for each task. This makes the model more flexible and easier to train. And also an obvious downside that it is hard to control the output of the model.
Model Link to heading
As for the actual model, T5 is an encoder-decoder transformer model that is more or less the same as introduced by vaswani2023attention.
The encoder uses a fully visible attention mask, which means that each token can attend to all other tokens in the input sequence. The decoder uses a causal attention mask, this is known from GPT like models, and means that each token can only attend to tokens that come before it in the output sequence, and has an additional cross-attention layer that allows the decoder to attend to the encoder output. As for positional encoding, T5 uses an relative positional encoding, where encode the relative position between queries and keys, and translate them into buckets. As for Layer Normalization we scale to unit variance but do not shift to zero mean. As for the Feed Feed Forward Network, it is a 2-layer ReLU network with an hidden size greater than the input size, with dropout before the activation and a dropout after the last projection. Booth attention and feed forward layers have a residual connection and are followed by layer normalization.
For an mockup of the model, you can check the following colaboratory notebook: T5 Mockup Here I do not implement the Positional encoding (you can find it here: Positional Buckets) but the rest should be more or less be the same.
Note: T5 being an encoder-decoder model, it does not mean we have to use it as an encoder-decoder model. We can allway just use the encoder by chopping of the decoder part, and introduce an additional classification head on top of the encoder output.
Objective Link to heading
The training objective is Span Corruption, where the model is trained to predict the original text given a corrupted version of the text. The corrupted version is created by replacing a span of text with a special token, and the model is trained to predict the original text given the corrupted text. This training objective is used to pretrain the model on a large corpus of text, and then fine-tune the model on a wide range of NLP tasks.
Performance Link to heading
Obviosly the state-of-the art results are no longer state-of-the art, but one important thing to note is the runtime requirements of T5, or more specifically encoder-decoder models compared to autoregressive models.
Lets assume we have an balanced encoder-decoder model, where the encoder and decoder have the same number of parameters. The role of the encoder is to process the input sequence (Prompt) and this is done only once, while the role of the decoder is to generate the output sequence, and this is done, token by token. If we compare this to an autoregressive model, this model has only a decoder, if this decoder has the same number of parameters as the whole encoder-decoder model, the runtime of the autoregressive model will be twice as long as the runtime of the encoder-decoder model. The reason is that the decoder in an autoregressive model is twice as big as the decoder in an encoder-decoder model.
Note: Although T5 is an encoder-decoder model, it doesn’t mean we have to use it as such. We can always just use the encoder by chopping off the decoder part and introduce an additional classification head on top of the encoder output.
FLAN Link to heading
FLAN takes T5 and introduces multiple finetuning tasks, including Chain of Though (CoT) instruction tuning (it is worth noting that this paper was first published in October 2022 before ChatGPT was introduced to the public in November 2022). The idea is to have this prompt guided general intelligence model that can be used in a wide range of tasks, and with the help of CoT finetuning we get a step-by-step reasoning model, that improves the performance of all other downstream tasks.
Back to Tiny Titans Link to heading
Let’s get back to the Tiny Titans paper. FLAN-T5 is the only encoder-decoder model they tested. Since the encoder uses a fully visible attention mask, it is no surprise that the model works well for the text summarization task. And since FLAN’s fine-tuning dataset involves a lot of summarization tasks, it is no surprise that the model works well for summarization tasks.
UL2 Link to heading
UL2 builds upon T5 and introduces a novel pretraining objective called the “Mixture of Denoisers.”
Mixture of Denoisers Link to heading
In the Mixture of Denoisers approach, we employ various denoising objectives, each designed to encourage the model to learn different types of knowledge.
R-Denosing Link to heading
The R-Denosing objective is inherited from T5. In this approach, we intentionally corrupt a “shortish” span of the input text and train the model to predict the original text based on the corrupted version. Specifically, we corrupt spans of 2 to 5 tokens, which accounts for approximately 15% of the text. The goal here is to impart useful knowledge to the language model, without necessarily emphasizing fluency in text generation.
X-Denosing Link to heading
UL2 introduces the X-Denosing objective. Here, we deliberately corrupt a “longish” span of the input text and train the model to predict the original text despite the corruption. The purpose is to challenge the model to generate coherent long text even when provided with limited information. Spans of 12 or more tokens (approximately 50% of the text) are subject to corruption in this case.
S-Denosing Link to heading
The S-Denosing objective aligns with the autoregressive Language Model (LLM) approach. We corrupt the input text by removing all tokens that appear after a certain token. Subsequently, the model is trained to reconstruct the original text from the corrupted version. This objective emphasizes the generation of fluent and coherent text.
To other relating papers Link to heading
We have previously explored how UL2 introduced multiple pretraining objectives. To further enhance this approach, we can introduce additional task-specific pretraining objectives.
CodeT5 and CodeT5+ Link to heading
CodeT5 introduces two additional pretraining objectives: Identifier Tagging and Masked Identifier Prediction.
Identifier Tagging Link to heading
The goal is to teach the model knowledge of whether if a code token is a identifier or not, and it can be viewed as sort of syntax hihglihting.
Masked Identifier Prediction Link to heading
Here we mask a random identifier and replace all its occurrences by a sentinel token. It can be viewed as a sort of code obfuscation, where if we change a name of a identifier it has no impact on the code. Technically this should teach the model to perform deobfuscation.
CodeT5+
CodeT5+ builds upon the foundation of CodeT5. It involves instruction tuning and utilizes both a shallow encoder and a deep decoder.
In the context of pretraining objectives, we distinguish between unimodal and bimodal pretraining. Bimodal pretraining incorporates both text and code, a strategy also employed in CodeT5. The goal is to equip the model with the ability to generate code from text (and vice versa). However, in the case of CodeT5, this approach led to reduced performance on code-to-code tasks, such as translating code from one programming language to another or detecting code defects.
For CodeT5+, the bimodal pretraining objectives include the following:
Text-Code Contrastive Learning Link to heading
In this objective, we work with positive and negative pairs of code and text. The idea is that for positive samples, the code and text representations should be close together in the representation space. This task activates only the encoder, which encodes the text-code snippets into a continuous representation space.
Text-Code Matching Link to heading
This objective exclusively activates the decoder. Its purpose is to predict whether the code and text share the same semantics. By doing so, the model captures fine-grained semantic information between code and text.
Text-Code Causal LM Link to heading
Here, both the encoder and decoder are engaged. The objective is to enable the model to generate code from text and vice versa.
AST-T5 Link to heading
AST-T5 represents an intriguing extension of T5 specifically designed for code. In this variant, we harness the power of the Abstract Syntax Tree (AST) associated with the code. Notably, a novel objective called AST-Aware Subtree Corruption is introduced. This objective involves corrupting tokens within a code snippet with respect to the corresponding subtree in the AST.
LENS: T5 in Network Security Link to heading
The LENS paper applies T5 for network security, and let me tell you, it’s quite the beast (I’m even planning to write a full blog post about it!). In a nutshell, the paper introduces multiple embedding strategies and pretraining objectives. While we won’t delve into the specifics of the embedding strategies (which include Payload Header Embedding and Packet Segment Embedding), we will certainly cover the pretraining objectives.
Packet Order Prediction Link to heading
In this pretraining objective, we focus exclusively on the Encoder. Our aim is to teach the model the natural order of packets within network traffic. To achieve this, we intentionally corrupt the order of the packets and then train the model to predict their original sequence.
Homologous Traffic Prediction Link to heading
Similar to the Packet Order Prediction, this objective is also applied solely to the Encoder. It draws inspiration from ET-BERT. The underlying idea is to equip the model with the ability to capture the difference between different types of network traffic.
Note: Interestingly, this paper takes a somewhat divergent approach compared to CodeT5+. While CodeT5+ emphasizes the decoder, here the focus is heavily skewed toward enhancing the encoder. The main reason for this is that in LENSE we are more interested in understanding the network traffic rather than generating it. Where in CodeT5+ we are more interested in generating code.
Takeaway Link to heading
T5, a robust base model, offers remarkable extensibility through the introduction of additional pretraining objectives. These supplementary objectives empower our model to grasp additional context, which can then be harnessed for more specific tasks. Theoretically, we can also apply these extra pretraining objectives to Causal LLMs (Language Models), although I have yet to encounter research in this particular direction. Given the dynamic landscape of language models, there is undoubtedly much ongoing exploration in the field, even though I don’t claim expertise in this area.
Furthermore, T5 boasts runtime requirements that are approximately half those of an autoregressive model (assuming a balanced encoder-decoder pair with equivalent parameters). But does T5 have any downsides? Technically, I don’t perceive any inherent drawbacks. Unfortunately, the current state-of-the-art results are still dominated by autoregressive models. However, this isn’t a limitation of T5 itself; rather, it reflects the prevailing trends in current research.
Disclaimer Link to heading
Since I am not an english native speaker, I use ChatGPT to help me with the text (Formatting, Spelling, etc). However I did write every single word in this blog post, If you are interested you can check the the original text here