Chow Liu Algorithm¶
The Chow-Liu algorithm a score based approach to find structure in bayesian networks. The algorithm finds the maximum-likelihood tree (since we limit ourselves to trees only, we do not need to have additional penalty terms) structure where each node has at most one parent.
Algorithm¶
Compute the mutual information for all pairs of variables X,U and form the mutual information graph where the edge between variable X, U has weight MI(X,U): $\( MI(X,U) = \sum_{x, u} = \hat{p}(x,u)\log [\frac{\tilde{p}(x,u)}{\tilde{p}(x)\tilde{p}(u)}] \)$
\(\tilde{p,u} = \frac{\text{count}(x,u)}{\# \text{data points}}\) is the empirical distribution This function measures how much information U provides about X.
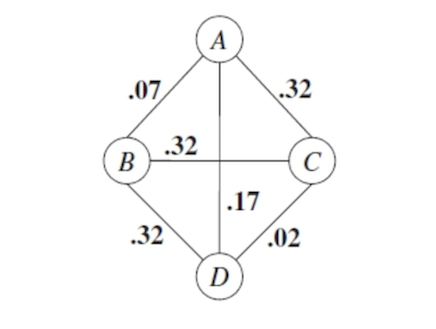
Find the maximum weight spanning tree (Kruskal or Prim Algorithm)
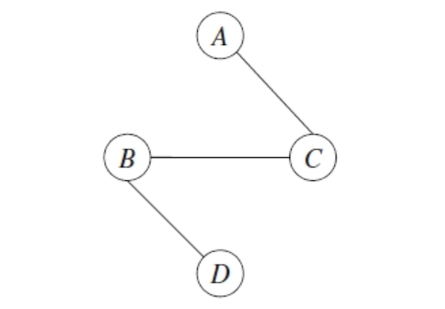
Pick any node to be the root, and assign directions radiating outward from this node (arrows from it), we get a directed graph.

The complexity is \(O(n^2)\) to compute all the mutual information pairs, and \(O(n^2)\) to compute tha maximum spanning tree.
Why it works?¶
The likelihood score decomposes into mutual information and cross entropy terms:
The entropies are independent of the ordering in the tree, only the mutual information weights with the choice of G.
If \(G=(V,E)\) is a tree where each node has at most one parent we get:
Mutual information is symmetric thus the orientation play no role.