Encoder Decoder Recurrent neural network¶
It is a recurrent neural network architecture, that maps an input sequence to an output sequence that has different length. This is common in speech, translation and question answering.
The input to the RNN is called the “context” C. And we want to produce a representation of this context (context can be a vector or a sequence of vector summarizing the input sequence \(x=(x^{(1)}, \cdots, x^{(n_x)})\))
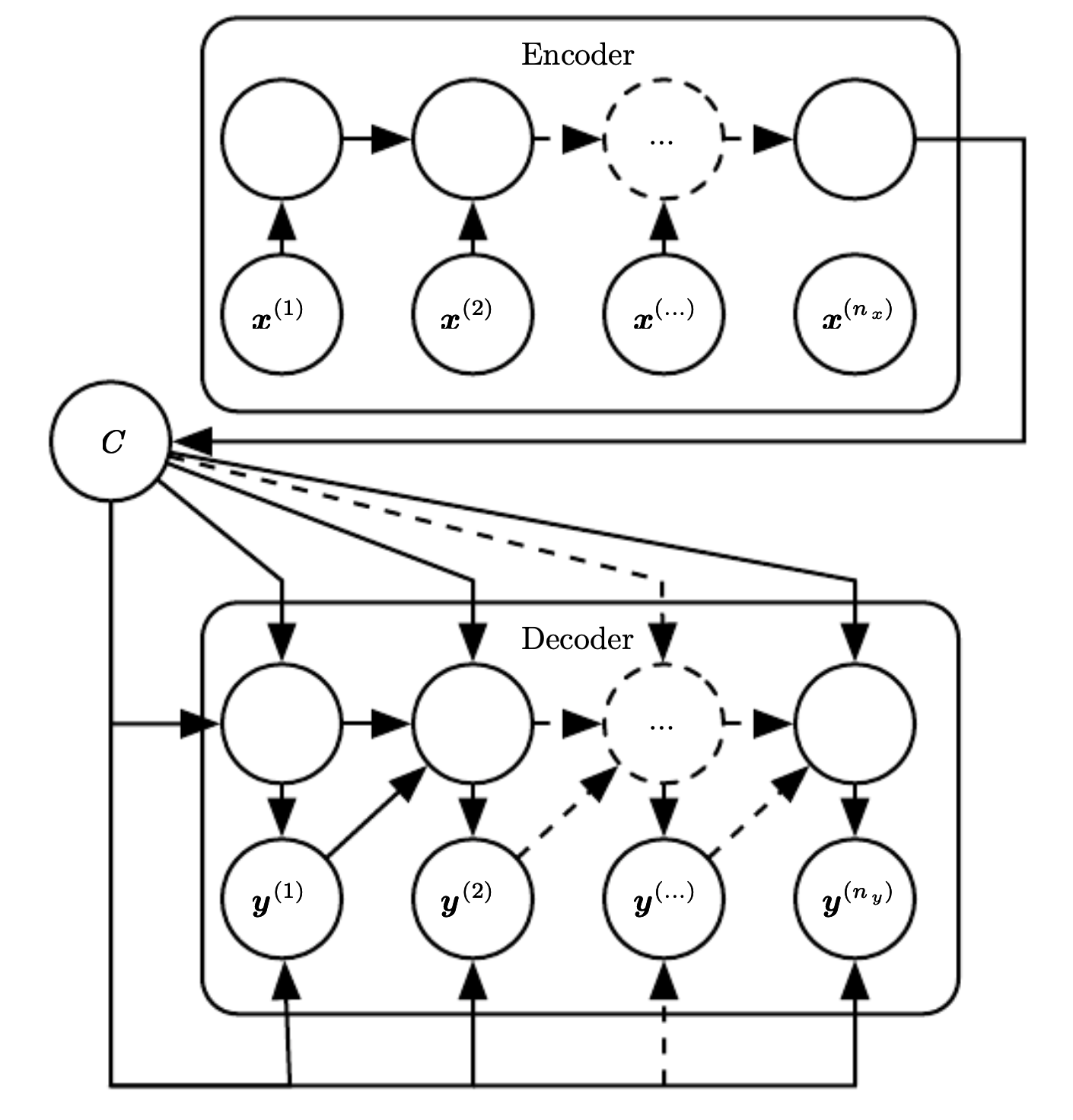
The encoder take the input, processes it and emit to context C. The decoder is conditioned on the fixed length context and produces an output sequence of potentially different length.
The main limitation is the fixed size of context C, we can overcome it using a variable length context. Or introducing attention mechanism that allow mapping from elements of C to the output sequence.