study-notes
Content
Signal to noise ratio
Distributed representation
Logistic regression
Empirical risk minimization
One dimensional motion
Structure learning
Fisher information matrix
Deep generative models
Beta distribution
PDF
Moments
Conjugacy
Properties
Conditional expectations
Gibs distribution
Bayesian view of exponential family
Softmax function
Slow feature Analysis
Model Averaging
Bayesian model selection
Forces in nature
Representation learning
Likelihood principle
Mechanical Energy
Rules Determinants
Expectations
Functions of random variables
Variance
Skew
Curtosis
Discrete random variables
Adam (adaptive moment estimation method )
Directed vs undirected graphical models
Algorithms and data structures
Newtons Laws
MAD
Graphical models
Manifold learning
Variational free energy
Conditional independence in
Markov Random Fields
Multiway Search Tree
Log partition function
Markov Random Fields example
Semi-Supervised Disentangling of causal factors
Second order methods
Newtons Method
Secant method
Quasi Newton
Multinomial coefficien
Sufficient statistics
Newtons Method
Log-sum-exp trick
Probability
Joint probability
Conditional probability
Union of mutliple events
Markov assumption
Tree traversal algorithms
First order Methods
Gradient descent
Conjugate gradient
Momentum
Nesterov momentum
Adagrad
RMS-Prop
Adam
Hyper gradient descent
Post order traversal
Encoder Decoder Recurrent neural network
Conjugate prior
MLE and MAP estimation for Generalized linear Models
Slice Sampling
Support vector machines (SVM)
Quadratic discriminant analysis (QDA)
Bernoulli-Gaussian Model
Gaussian mixture model EM
Trust region method
Black-box variational inference
Binomial distribution
Conjugacy
Multinomial
Chow Liu Algorithm
Empirical Bayes
Neural Networks
Kernel machines
Inference in
hidden markov models
Forward-Backward
MAP estimation (Viberty)
SVM
classification
Unsupervised learning
Work
RNN as a directed graph
Red-black tree
to
2-4 tree
Contractive
autoencoder
(CAE)
Mean filed method
Hypergradient Descent
Physics
Neural networks parameter initialization
Linear factor model
Latent Variable Models
Greedy layer wise unsupervised pre-training
Learning Markov Random Fields
Elipse
Sampling from standard distributions
Map inference in graphical models
Search Trees
Ordinary Least Squares (MLE)
Rejection sampling
Bridge regression
Structured support vector machines
Multivariate Gaussian
MLE
Join Gaussian:
Maximum entropy distribution
Mixture density networks
Stochastic Encoder and Decoders
Probability tables
Linear programming
Adagrad (Adaptive subgradient method)
Jensens inequality
Newtons law of gravitation
\(l_1\)
regularization
Fitting
Variants
Hadamard Product
Local descent
Collaborative Filtering
Dirichlet Multinomial model
Bayeisan decision theory
Steps of HMC iteration
The EM Algorithm
Gradient clipping
Probability chain rule
Normal Inverse Chi Squared
Uninformative prior
Sequential importance sampling
Information theory
Large margin principle
Multinoulli exponential family
Graph
Mercer (positive definite kernels)
Inverse Wishart distribution
Catastrophic forgetting in
neural networks
PMF/PDF of a function of random variables
Continuous
Autoencoders
Mixture of Gaussians
Subgradient
Naive Bayes Classifier
Neural network universal approximator
Hierarchical adaptive lasso
Matrix multiplication
Gaussian process latent variable model
Potential Function
Kernel density estimation (KDE)
Probabilistic matrix factorization
Entropy
Joint entropy
Total mechanical energy
Adams Law
Power
Markov chain Monte Carlo (MCMC) inference
Potential Energy
Bayes rule
Cholesky Decomposition
Markov models
Relative velocity
Mahalanobis distance
Generalized linear models
Motion in plane
Mixture models
Parameter estimation
Variational inference
Junction tree algorithm
Cumulative distribution function
Linear Gaussian systems
Robust linear regression
Whitening or sphereing
Biparite graph
Posterior distribution
Sumarizing the posterior distribution
Recurrent neural networks conditioned on context
RMS Prop
D-separation
alternative for Markov Random Fields
Ridge regression
connection to
PCA
Jeffrey prior
Survival function
Feed forward Neural Network (Multilayered perceptron MLP)
Gibbs sampling
Plate notation
Soft threhsolding
Non Identifiable models
Noise-free
Gaussian Process Regression
Variable elimination algorithm
Bidirectional Recurrent neural networks
Teacher Forcing
Elastic Forces
Splay trees
Shannon infromation content of an outcome
Rao Blackwell theorem
Trees
Monte Carlo approximation
Forward vs reverse KL divergence
EM For PPCA
Inequalities
Matrix vector addition
Proximal algorithms
Proximal gradient method
Principal component analysis
Probabilistic PCA
Posterior predictive distribution
Order statistics
Kullback-Lieber divergence (KL)
Schur Complement
Sum-product message passing
Excess error
D-separation (Directed-Separation)
Maximum entropy derivation
Noisy Gaussian process Regerssion
Importance sampling
Projectile Motion
Equivariante function
Conditional random fields (CRFs)
Dropout
SVM classification EXAMPLE cvxpy
Derivation of BIC
Toeplitz matrix
Map estimation
Credible intervals
Highest posterior density (HDP)
Hamiltonian monte carlo
Junction tree example
Linear Regression
Fiting linear regression
Hamiltonian Monte Carlo Tunning parameters
Polyak Averaging
Batch and mini-batch algorithms
Wolfe Conditions
Uniform circular motion
Predictive sparse decomposition
Hammersley-Clifford
Recursive neural network
Parameter estimation for mixture models
EM
Area and Volume
Mixture of multinoullis
Clustering
Mixtures of experts
Computing the marginal likelihood (evidence)
Bic approximation of marginal likelihood
Multi-class Logistic Regression
Bernoulli distribution
Variational bayes
Regularization
Unscented transform
Simsons Paradox
Estimator
0-1 Loss
Rejection option
\(l_2\)
loss
\(l_1\)
loss
Student T
Moments
Connections to Cauchy/Lorentz
Distribution
Symetry arround arguments
t-distribution in place of the Normal for bayesian modelling
t -distribution as a mixture of Normals
Variable elimination example
Chi-Squared distribution
Connection to Gaussian
Connection to
Gamma
Learning
Sparse autoencoder
Hinge loss
Tangent distance
Variational bayes EM
Kalman smoothing algorithm
Non-Linear, non-Gaussian SSMs
Ridge regression (Penalized least squares)
Gamma Function
Gaussian distribution
Poisson process
This is an test
Law of large numbers
Variance stabilizing transformation
Matrix inverse
Information norm
Kernel function
Generative Adiversal Networks (GAN)
Maximum Likelihood Learning (Estimation)
Variable elimination motivation
Linear discriminant analysis
Regularization
Structured predictions
Max-product message passing
Bayesian t-test
Clustering
Smoothness regularization
Adversarial training
Determinant
Under complete autoencoder
Bonferroni Correction
Balanced Search Trees
Energy based models
Kalman filtering algorithm
Prediction step
Measurement step
Posterior predictive
Computational issues
Conservation of energy
Graph cut MAP inference PGM
Random Variables
Monte carlo inference
Evidence lower bound (ELBO
AVL tree
Poisson distribution
Properties
EM Theory
Association Rules
LSTM
Univariate Gaussian exponential distribution
Principal Component as a Manifold
Force and motion
Optimization in deep learning
Convolution
Law of total Probability
Bayes factors
Gamma distribution
Moments
Properties
Sum of 2 Gamma distributions
Connection to Exponential distribution
Connection to Beta distribution
Erlang distribution
Exponential distribution
Memory less property
Connection to Gamma
Poisson process
Back-propagation through time
Comparing gaussian processes to other models
Red black trees
Las Vegas Algorithms
Why HM works
Sigmoid and Softplus
Hidden units in neural networks
Auto-encoding variational Bayes
Classical PCA
Markov chain monte carlo accuracy
Laplace distribution (Double exponential)
Moments
Gradient descent
Bayesian linear regression
Leaky Unis
Singular value decomposition (SVD)
Infering the parameters of an NVM
Inclusion Exclusion Probability
Denoising
autoencoder
(DAE)
Vector
Independence
Bayesian occam’s razor.
Factor analysis unidentifiability
Learning in conditional random fields
Metropolis Hastings
Uniform distribution
Universality
Uninformative prior
L1 regularization sparse solution
Contact Force
Computer Vision neural networks
Gated Recurrent Units
Convolution operation
EM as variational inference
PCA for categorical data
Supervised PCA (Bayesian factor regression)
Partial least squares
Canonical correlation analysis
Belief propagation
Probit regression
Convex set
Page Rank
Numerically stable ridge regression computation
Inverse Gamma
PDF
Moments
Conjugate gradient
Black Holes
Boostrap
False positive vs false negative tradeoff
Cross correlation
Numeric computation
Independent component Analysis (ICA)
Binary Tree
Bernoulli distribution exponential family
Bayesian Learning
Wishart distribution
Example:
Sum of squares
Epigraf
Dirac measure / Dirac delta
Batch Normalization
Kronecker product
Comparing OLS with Ridge and Lasso
Quasi Newton
Elastic Net (ridge and lasso combined)
Jacobian
Sparse Linear models
Multi-task learning
Gaussian Process
Mutual information
Point wise mutual information
Continuous random variables
Bayes Error
Factor analysis (FA)
Unidentifiability
Stationary distribution
Unfolding an Computational Graph
Functions of random variables
Linear functions
Dirichlet distribution
Restricted
Boltzman Machine
Priors
K-medoids
Transfer learning and domain adaptation
State space models (SSM)
Long term dependencies in
RNN
Loopy belief propagation (LPB)
Output units in neural networks
Graph cut
Hessian
Bootstrap aggregation (Bagging)
Convex Functions
Strict convexity
Operations that preserve convexity
Convexity in higher dimesnions
SVM
for regression.
QR decomposition
Kernels for document comparison
Marko chain monte carlo convergence
Trace Operator
Persistent contrastive divergence
Matrix inversion lemma
Variational auto-encoder
Central Limit Theorem
Kernels derived from probabilistic generative models
Tangent prop
Maximum likelihood markov random fields
Chordal graph
Pareto distribution
Moments
Laplace (Gaussian) approxiation
Sparse coding
Weight
Sampling from graphical models
Covariance
Correlation (Pearsons correlation coefficient)
Dirichlet Compound Multinomial
Usage
Hierarchical bayes (multi-level model)
Acceleration
(2,4) Trees
Directed graphical models
Examples
Back propagation
Deep recurrent neural networks
Probability mass functions
Probability density function
Kernel trick
Bias Variance tradeoff
Terminal conditions
Metropolis Hastings mathematical formulation
Hybrid discrete/continuous SSMs
Basic trigonometry
Quadratic formula
Logarithms and exponentials
Exponential family sufficient statistics
Generalized linear mixed models
Deep learning guide line
Inference
Einsum
Affine function
Conditional independence
MLE for Bayesian Networks
Inference in joint Gaussian distribution
Rectified linear units (RELU)
Gaussian Process Regression
Bayesian Statistics
Drag Force
Hidden Markov models
Optimality conditions for the lasso
Exponential family
Automatic symbolic differentiation
Reverse accumulation
Line search
Satellite motion
Learning for LG-SSM
Regularization in Neural Networks
Sample variance
Common recurrent neural network architectures
Learning manifolds with autoencoders
Span of a set of Vectors
Poison regression
Bayes Biliard
Markov random field (MRF)
Beta function
Gama function
Higher order derivatives in neural networks
Metropolis hastings proposal distribution
LARS (homotopy methods)
Empirical Distribution
Empirical CDF
Factor graph
Qda to LDA
Recurrent neural networks (RNN)
Coordinate descent
Activation functions
Gaussian discriminant Analysis
Beta binomial model
Independence Map of a Graph
.md
.pdf
Epigraf
¶
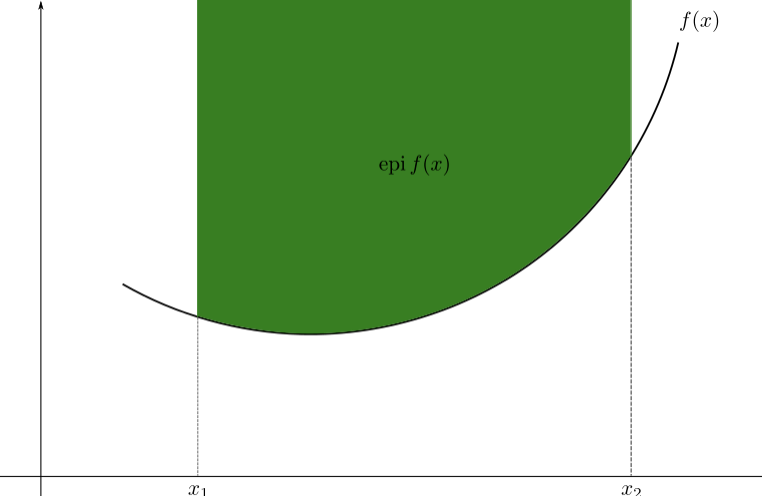
Epigraf of a function
\(f(x)\)
are all the points that lie above the function:
Sum of squares
Dirac measure / Dirac delta