// TODO Shorten
First order Methods¶
First order method rely on the gradient information to select the direction of descent.
Gradient descent¶
The direction of steepest descent is an obvious choice for the descent direction \(d\).
Conjugate gradient¶
It borrows inspiration from methods that optimize quadratic function:
\(A_{n\times n}\) is symmetric and positive definite thus \(f\) as a unique global minimum.
This can be optimized in \(n\) steps.
Momentum¶
Gradient descent will take a long time to traverse a nearly flat surface:
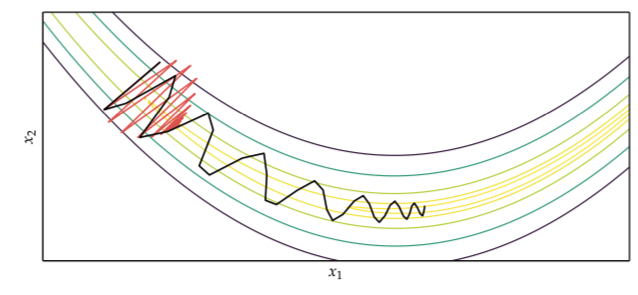
We can speed up the progress by adding momentum:
Nesterov momentum¶
One issue with momentum is that it does not slow down enough at the bottom of the valley and tend to overshoot the bottom. Nesterov ads an modification that decreases the momentum in higher iterations:
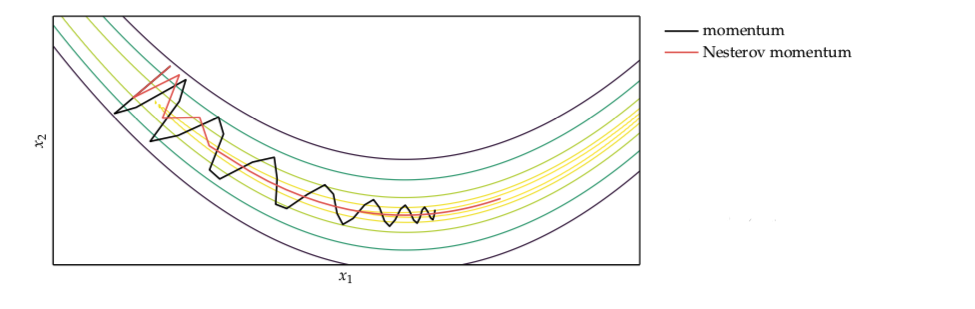
Algorithm¶
Initialize: \(\alpha\) learning rate, \(\beta\) momentum decay, \(v = 0\) momentum
Iterate: \(v = \beta v - \alpha \nabla f(x + \beta v)\)
return \(x\)
Hyper gradient descent¶
The rough idea is that we apply gradient descent to the learning rate.