LSTM¶
A gated recurrent neural network where the gradient can flow for a long duration. The weights in the self loop depend on the context, and is gated (controlled by a different hidden unit). The same time scale of integration can change dynamically even if the parameters are fixed.
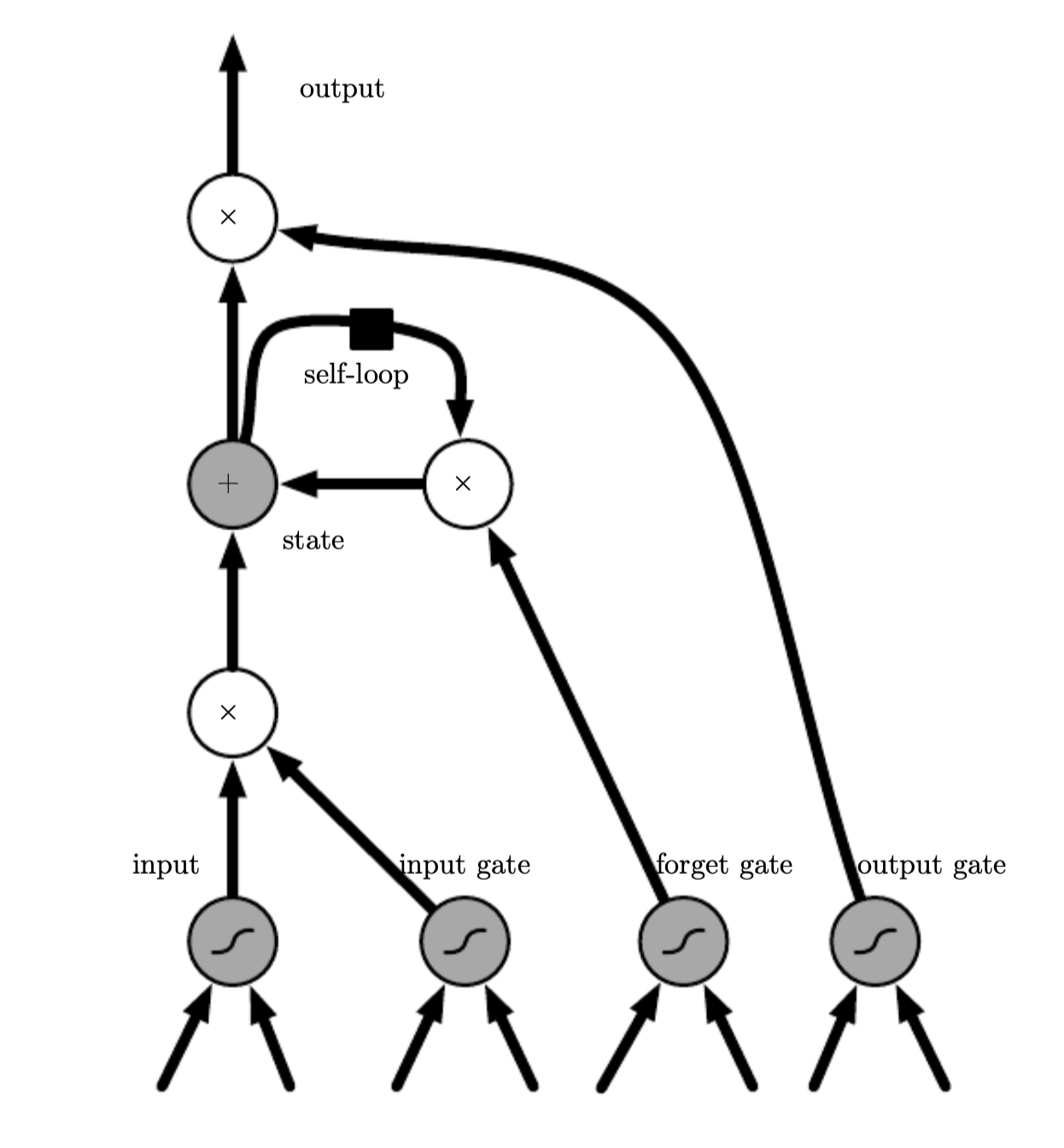
LSTM cells have internal recurrence (self loops) in adition to the outer recurrence of the RNN. Each cell has the same input and output as a RNN, but in addition it has more parameters and a system of gating units that control the flow of information. The most important component is state unit \(s^{(t)}\), which has a linear self-loop weight, similar to leaky units This self loop is controlled by a forget gate unit \(f^{t}_i\) (t - timestep, i - cell) which sets this weight to value between (0,1) with a sigmoid unit:
\(x^{(t)}\) is the current input vector
\(h^{(t)}\) the current hidden layer containing the output of all the LSTM cells
b^f, U^f, W^f are the bias, input weights and recurrent weights for the forget gate
The internal state is updated similarly:
b, U, W are the bias, input weights and recurrent weights into the LSTM cell
\(g_i^{(t)}\) is the external input gate
The output \(h^{(t)}\) can be shut down trough the output gate \(g^{(t)}_i\)