Mixture of multinoullis¶
A mixture model where the data consists of D-dimensional bit vectors. The class conditional density is a product of Bernoullis
\(\mu_{ij}\) is the probability that bit j turns on in cluster k.
The mean and covariance of this mixture model is given by:
\(\Sigma_k = diag(\mu_{jk}(1 - \mu_{jk}))\)
Here the mixture distribution can capture correlations between variables.
Clustering¶
We can use a mixture model to create a generative classifier, where we model each class-conditional density \(p(x|y=c)\) by a mixture distribution.
We fit a mixture model, and compute \(p(z_i = k| x_i, \theta)\) which represetns the posterior robability that the point i belongs to cluster k. This is known as the responsibility of cluster k for point i and can be computed as:
This is also known as soft clutering. We can transform it into hard clustering by using the MAP estimate by approximating
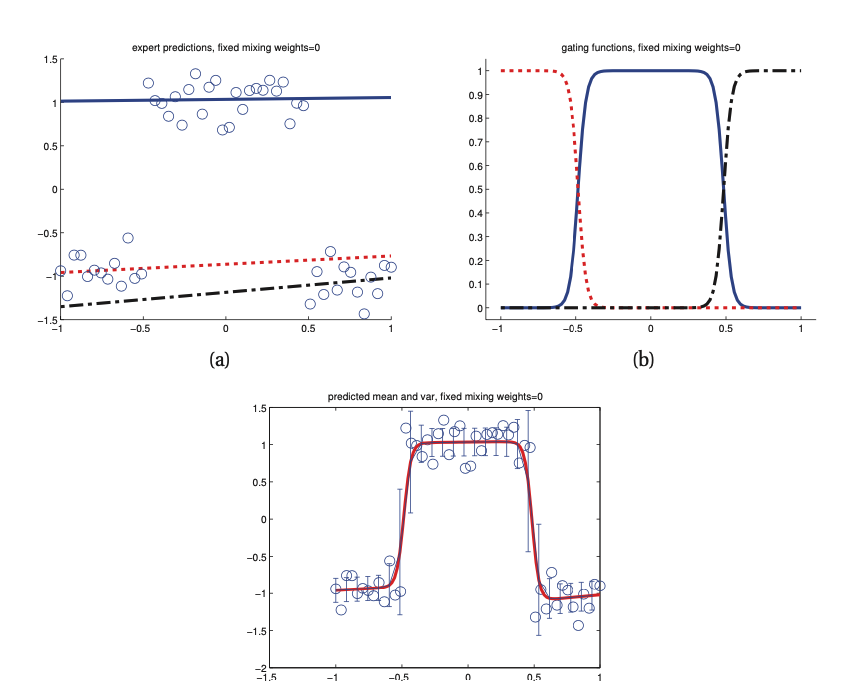
Mixtures of experts¶
We can use mixtures models for discriminative classification or regression. In this example we fit 3 different linear regression functions, each applying to different part of the input space.
This is called a mixture of experts.