Ridge regression connection to PCA¶
We showed that if we perfrom SVD on \(X = USV^T\) then we have:
Our ridge estimation becomes:
Where: $\(\tilde{S}_{jj} = [S(S^2 + \lambda I)^{-1}S]_{jj} = \frac{\sigma^2_j}{\sigma^2_j + \lambda }\)$
\(\sigma_j\) are the scalar values of \(X\)
Hence:
Comparing it to least squares:
In the case that \(\sigma^2_j\) is small compared to \(\lambda\) \(u_j\) will not have much effect on the prediction. Hence we can say that the direction in which we are most uncertain about \(w\), are determied by the eigenvectors of this matrix with the smalles eigen values. Hence a small singular value corresponds to directions with high posterior variance, and in these directions ridge shrinks at the most.
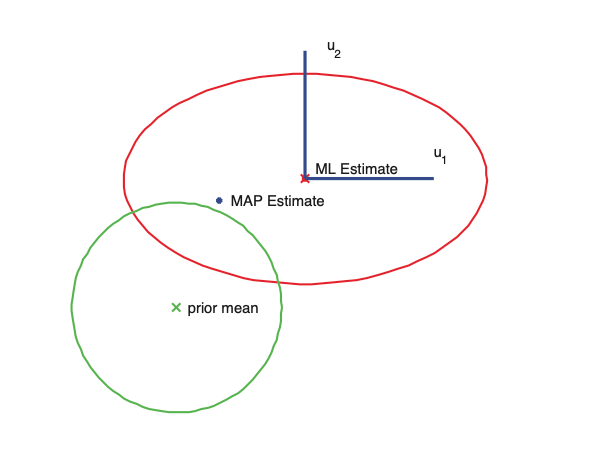
The horizontal \(w_1\) parameter is not-well determined by the data (has high posterior variance), but the vertical \(w_2\) paremter is well determiined. Hence \(w_2^{\text{map}}\) is close to \(\hat{w}_2^{\text{mle}}\) but \(w_1^{\text{map}}\) is shifted strongly towards the prior mean