Recurrent neural networks (RNN)¶
Specialize on processing an sequence of data \(x^{(1)}, x^{(2)}, \cdots, x^{(\tau)}\) and they share the same weight across multiple time steps.
In RNN each member of the output is the function of the previous member of the output and is produces using the same update rule applied to the previous outputs. Because of this we can share parameters across a very deep computational graph.
Many recurrent neural networks are of the form:
\(h\) are the hidden units representing the state of the neural network
\(x^{(t)}\) is an external signal
This kind can be express and unfolded as the following graph:
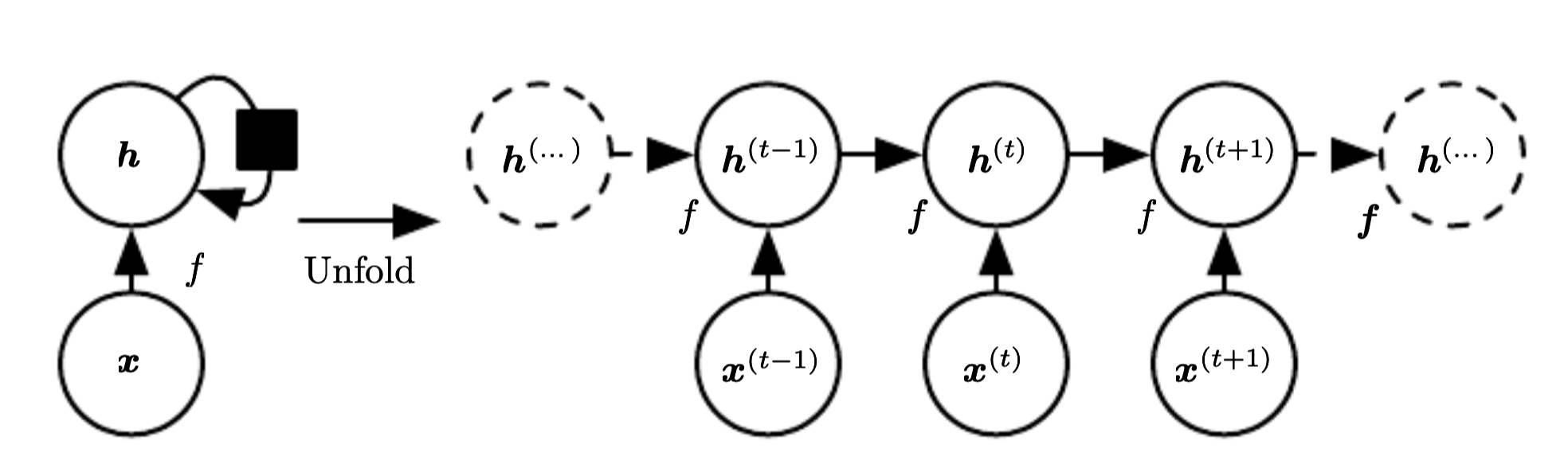
Most RNN are more complex, they read the hidden state and make predictions to the output units.
Recurrent neural networks learn \(h^{(t)}\) to perform lossy summary of task-relevant aspects of the past sequence of inputs up to \(t\). It has to be lossy since it maps an arbitrary length sequence to an fixed length vector.
We can represent the unfolded recurrence after \(t\) steps with a function \(g^{(t)}\)
\(g\) takes the whole past sequence \(x^{(t)}, \cdots, x^{(1)}\) as input and produces the current state. The unfolded recurrence allows the factorization of \(g^{(t)}\) into repeated application of a function \(f\). The unfolded process introduces mayor advantages.
The learned model \(f\) has to learn only a transition from one state to the other. It does not depend on the length of the input. Thus it allows us to handle variable length inputs.
We can reuse the same transition function \(f\) with the same parameters at every step.
The fact that we have to learn only a single model \(f\) that operates on all time steps, allows to handle sequence lengths where not observed in the training data.
Common architectures¶
There are multiple ways to define a recurrent neural network.
RNN as a directed graph¶
We can view recurrent neural networks as a directed graph.
Generating data from RNN¶
We want to generate future sequences. The main difficulty is to determine when to stop the generation of the next sequence. There are some common approaches:
Include a special sign in the sequence determining the end
Learn a Bernoulli output to determine if we keep generating
We can train the model also output the length as an extra output.
Conditioned on context¶
Recurrent neural networks can tak additional input.
Bidirectional recurrent neural networks¶
Combines two recurrent neural networks.
Encoder-Decoder RNN¶
We map an input sequence, to an output sequence of different length.
Deep recurrent neural networks¶
We have recurrent connection on multiple levels.
Long term dependencies¶
Long term dependencies propose a challenge in recurrent neural networks.
Gated RNN¶
Create paths trough time that do not vanish nor explode. They generalize leaky units where the connection weights can change over time. We are allowed to accumulate information for a long duration, and when it is not needed it can forget the old state.