Gradient descent¶
The direction of steepest descent is an obvious choice for the descent direction \(d\). Following this direction we are guaranteed to improve if the objective function is smooth and the step size is sufficiently small. The direction of steepest descent is the direction opposite to the gradient.
\(x^{(k)}\) is the design point at the kth iteration
We typically normalize the direction of the steepest descent
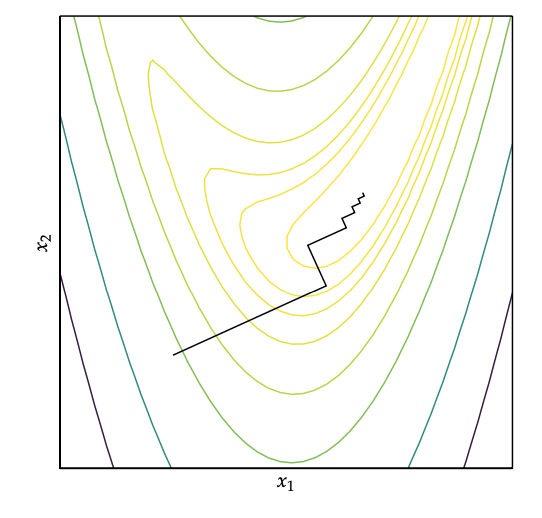
If we choose the step size that leads to maximal increase in f. This direction is always orthogonal to the current direction, and it will lead to an jagged search path.
We can prove this by first starting with the following minimization:
We have to find the gradient with respect to \(\alpha\) and set it to zero:
Now we know $\( d^{(k=1)} = \frac{\nabla f(x^{(k)} + \alpha d^{(k)})}{|| \nabla f(x^{(k)} + \alpha d^{(k)}) ||} \)$
We can substitute it in the equation before:
Here we can drop the \(-\) sign and the normalization since it wont change the fact that the vectors are still orthogonal.
Algorithm¶
We require \(f, \nabla f\) and a learning rate \(\alpha\)
for each iteration i:
\(g_i = \nabla f(x^{(i)})\)
return \(x_i - \alpha \cdot g_i\)
Convergence¶
If we want stochastic gradient descent to converge we need the learning rate to be: $\(\sum_{k=1}^{\infty} \alpha_k = \infty, \sum_{k=1}^{\infty} \alpha_k^2 \le \infty \)$
Excess error¶
The excess error after \(k\) iterations of gradient descent for convex problems is \(O(\frac{1}{\sqrt{k}})\) and \(O(1/k)\) for strong convex problems.
Stochastic gradient descent¶
The key insight is that gradient descent is an expectation, the expectation can be approximated using a small set of samples:
\(m'\) is an minibatch
The update rule becomes:
\(\epsilon\) is the learning rate
Gradient descent has no guarantee to find a local optimum, but in practice it finds an low enough value quickly enough to be useful.