Multivariate Gaussian¶
Extends the gaussian distribution into higher dimensions.
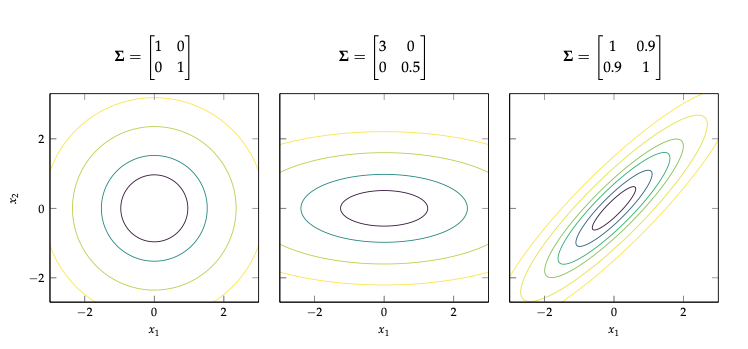
Now we focus on the term in the exponent:
We can view \((x - \mu)^T \Sigma^{-1} (x - \mu)\) as the Mahalanobis distance of \(x\).
If we perform eigen value decomposition on \(\Sigma\) we get:
Hence we can see that:
where:
\(y_i \triangleq u_i^T(x - \mu)\)
Hence we can see the connection between an elipse in 2d:
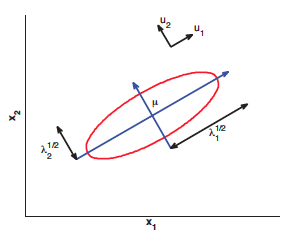
Here the eigen vectors determine the orintation of the ellipse, and the eigen values determine how elogonated it is.
In general, we see that the Mahalanobis distance corresponds to Euclidean distance in a transformed coordinate system, where we shift by \(\mu\) and rotate by U.
MLE¶
Given we have N i.i.d samples \(x_i \sim \mathcal{N}(\mu,\sigma)\) then the MLE for parameters is:
Which are only empirical means.
Join Gaussian:¶
We can express \(a,b\) marginaly as: $\( a \sim N(\mu_a, A) \\ b \sim N(\mu_b, B) \)$
The conditional distribution \(a|b\) has the form:
Example:

Maximum entropy distribution¶
Gaussian distribution is the maximum entropy distribution for any distribution if we are willing to assume that a distriibution has a mean and covariance.