SVM for regression.¶
We enforce sparsity by using for the loss function a variant of Hubert loss function called the epsilon insensitive loss function defined as:
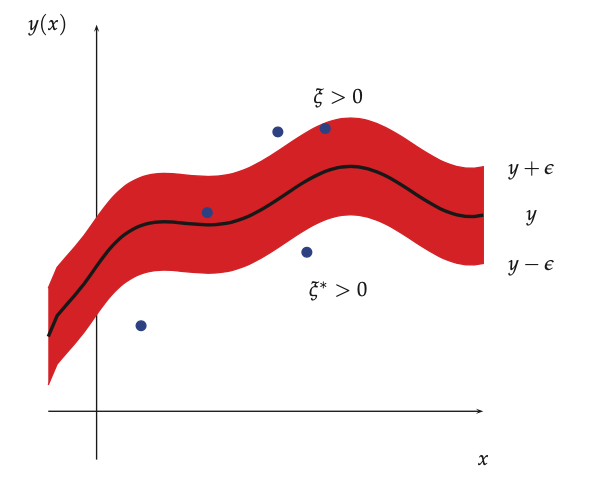
This means that any point lying inside an \(\epsilon\)-tube around the prediction is not penalized
Our loss function is of the form:
\(\hat{y}_i = f(x_i) = w^Tx_i + w_0\)
\(C = 1/\lambda\) (regularization constant)
This objective is convex and uncontrained, but it is not differentiable, because of the absolute value function in the loss term. The get arround this problem we reformulate this as a contrained optimization problem, by introducing slack variables to represent the degree to which each point lies outside the tube.
We can rewrite the objective as:
This is a quadratic function of w, and must be minimized subject to the linear constraints, as well as the positivity constraints \(\xi_i^+ \ge 0\)and \(\xi_i^- \ge 0\), hence this is a quadratic program.
Where the optimal solution has a form:
\(\alpha_i \ge 0\)
The vector \(\alpha\) is sparse, since we do not care about errors which are smaller than \(\epsilon\). Values of \(x_i\) for which \(\alpha_i \ge 0\) are called support vectors, those are the points for which the errors lie on or outsie the \(\epsilon\) tube.
To make predictions we can use the trained model as:
Hence we get a kernellized solution.